The landscape of synthetic media shifted fundamentally on April 15, 2026, as Google DeepMind announced the official release of Gemini 3.1 Flash TTS, a text-to-speech engine designed to bridge the long-standing "uncanny valley" of robotic narration. While previous iterations of artificial intelligence (AI) voice generation focused primarily on clarity and linguistic accuracy, Gemini 3.1 introduces a paradigm shift by functioning as a digital speech director rather than a mere synthesizer. This advancement allows developers and creators to inject nuanced human emotion, variable pacing, and complex multi-speaker dynamics into audio projects using simple API calls or the Google AI Studio interface.
For years, the primary criticism leveled against AI voice technology was its inherent lack of "soul." Traditional systems processed text phrase by phrase, often resulting in a monotonous delivery that failed to capture the subtext of a script. The release of Gemini 3.1 Flash TTS addresses these limitations by utilizing a transformer-based architecture capable of interpreting "stage directions" embedded within text. By recognizing emotional cues and context, the model can adjust its prosody, pitch, and breath patterns to match the intended sentiment of the content, effectively ending the era of the "robotic" assistant.
The Evolution of Synthetic Speech: A Chronology of Innovation
The journey to Gemini 3.1 Flash TTS is rooted in over a decade of research at Google and DeepMind. In the mid-2010s, Google’s WaveNet set the standard for high-fidelity audio by using neural networks to generate raw audio waveforms. This was followed by the Tacotron and Durian models, which improved the efficiency of converting text to spectrograms. However, these models remained largely "static," requiring significant manual post-production to achieve emotional resonance.
By 2024, the integration of Large Language Models (LLMs) with speech synthesis began to allow for better context awareness. The breakthrough came in late 2025 with the internal testing of the Gemini 3.0 series, which experimented with "native multimodal" outputs. The 3.1 Flash update, released this spring, represents the commercial culmination of these efforts, optimizing the model for low-latency performance without sacrificing the complex emotional intelligence required for high-end creative work.

Technical Specifications and the "Speech Director" Framework
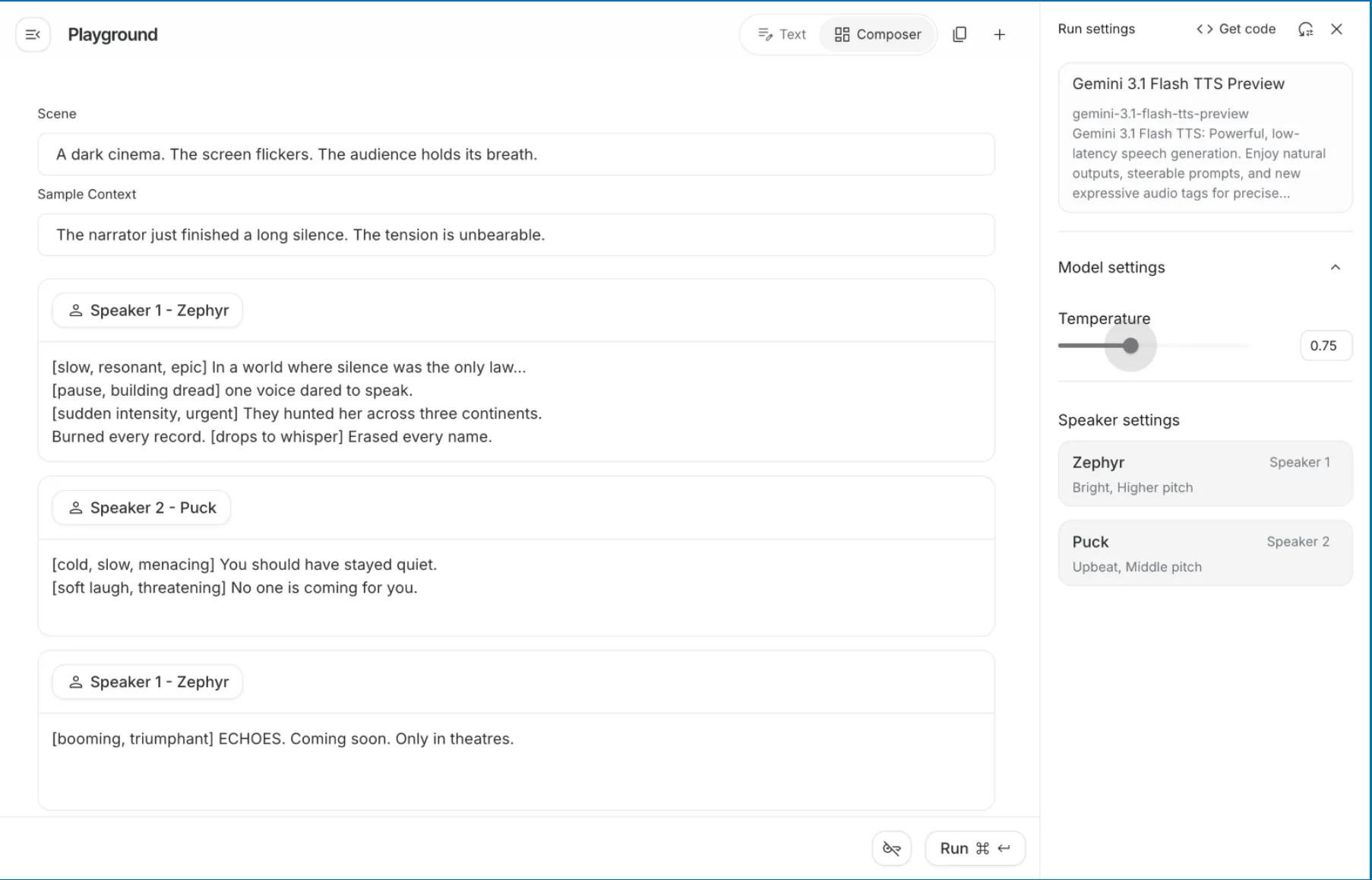
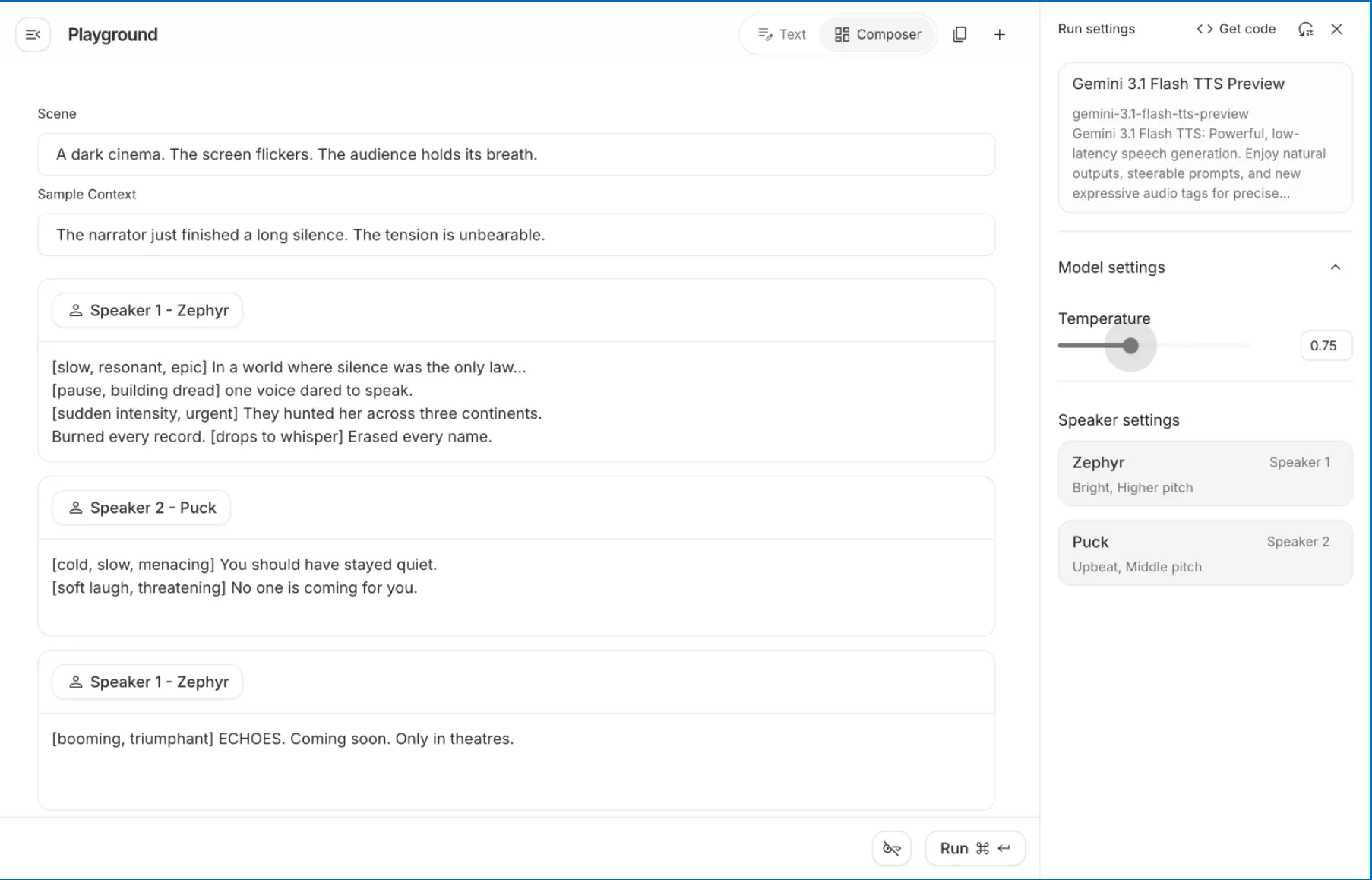
The defining feature of Gemini 3.1 Flash TTS is its ability to interpret native audio tags. Unlike previous systems that relied on complex SSML (Speech Synthesis Markup Language) tags—which were often cumbersome and limited in scope—Gemini 3.1 uses natural language descriptors within brackets or scene blocks. This allows the AI to understand instructions such as [whispering], [building tension], or [joyful laughter] as part of the generative process.
Key technical enhancements include:
- Native Multi-Speaker Synthesis: The model can generate audio files featuring multiple distinct voices with different personalities and accents within a single API request, eliminating the need for separate calls and manual stitching.
- Contextual Prosody: By analyzing the surrounding text, the AI can infer the appropriate tone. If the text describes a dark, eerie setting, the model automatically adjusts the baseline delivery to be more hushed and deliberate.
- Expansive Language Support: Launching with support for over 70 languages and regional dialects, the model ensures that emotional nuances are not lost in translation.
- High-Speed Inference: The "Flash" designation indicates that the model is optimized for real-time applications, making it suitable for interactive gaming, live translation, and responsive AI avatars.
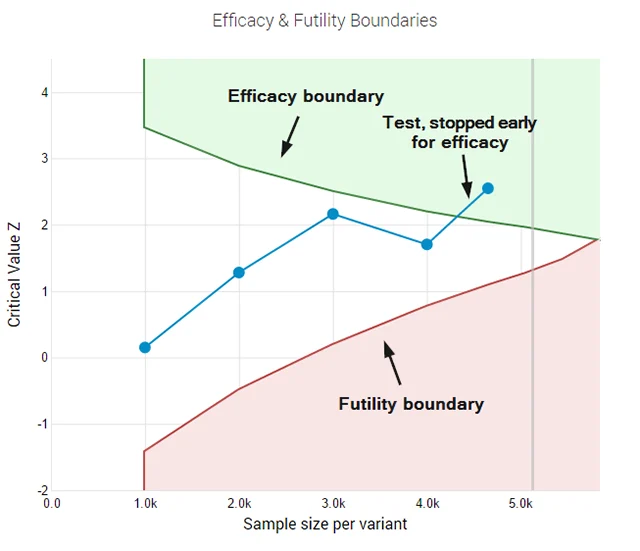
Benchmarking Performance: The Artificial Analysis TTS Arena
To validate the efficacy of Gemini 3.1, Google DeepMind submitted the model to the Artificial Analysis TTS Arena, the industry’s most rigorous independent benchmark for synthetic speech. The arena utilizes a "blind" human preference testing methodology, where thousands of participants listen to audio samples from competing models and vote on which sounds more natural without knowing the source.
The results positioned Gemini 3.1 Flash TTS at the top of the leaderboard with an Elo score of 1,211. This score significantly outpaces established competitors. For comparison, ElevenLabs Multilingual v3 holds an estimated score of 1,150, while OpenAI’s TTS HD and Azure’s Neural TTS trail with scores of 1,090 and 1,020, respectively. The data suggests a growing human preference for models that prioritize emotional delivery over mere phonetic precision.
Practical Applications and Development Workflows
The versatility of Gemini 3.1 Flash TTS is best demonstrated through its immediate applicability in three distinct sectors: publishing, broadcasting, and cinematic production.

1. Automated Emotional Audiobook Production
Traditional audiobook production is a costly and time-consuming endeavor, often requiring weeks of studio time. Using the Gemini API, developers can now build programs that convert plain text into "performed" narrations. By utilizing the Python SDK, a creator can script a story where the narrator’s voice shifts from a calm, hushed tone during an introduction to a sharp, fast-paced delivery during an action sequence. This level of control allows for the mass production of high-quality literary content that remains engaging to the listener.
2. Multi-Host Podcast Generation
The multi-speaker feature allows for the creation of "synthetic podcasts" where two or more AI personalities can debate, joke, or interview one another. Because the model handles speaker transitions natively, the resulting audio maintains a natural conversational flow, including the slight overlaps and reactive sounds (like chuckling or "hmm" sounds) that characterize human interaction. This has significant implications for news organizations looking to provide daily audio summaries of printed articles.
3. Cinematic Voice-Over and Directing
Through Google AI Studio, users who lack coding knowledge can act as "creative directors." By setting a "scene" (e.g., a dark movie theater) and providing speaker profiles, users can generate movie trailers or character dialogue with specific dramatic flair. The ability to overwrite a speaker’s default pitch with mood tags—transforming an "upbeat" voice into a "cold, menacing" villain—provides a level of creative agency previously reserved for professional sound engineers.
Safety and Ethics: The Role of SynthID
As synthetic audio becomes indistinguishable from human speech, the potential for misuse in deepfakes and misinformation campaigns increases. Addressing these concerns, Google DeepMind has integrated "SynthID" into every audio file generated by Gemini 3.1. SynthID is an imperceptible digital watermark embedded directly into the audio waveform.
Unlike metadata, which can be stripped away, SynthID remains detectable even after the audio has been compressed, edited, or recorded through a secondary microphone. This technology provides a critical layer of transparency, allowing platforms and users to verify whether an audio clip was produced by a human or generated by an AI. This move has been praised by digital rights advocates as a necessary step in maintaining the integrity of the information ecosystem.
Competitive Landscape and Market Impact
The release of Gemini 3.1 Flash TTS places Google in direct competition with specialized startups like ElevenLabs and enterprise giants like Microsoft and OpenAI. While ElevenLabs remains a leader in high-fidelity voice cloning, Google’s offering is being positioned as the superior choice for "expressive" and "creative" applications due to its native integration of emotional controls.
Market analysts suggest that the "all-in-one" nature of the Gemini API—handling multi-speaker dialogue in a single call—will likely reduce operational costs for startups. Whereas previous workflows required multiple API calls and post-production software to stitch voices together, Gemini 3.1 streamlines the pipeline, potentially disrupting the current pricing models of the synthetic speech market.
Broader Implications for the Creative Economy
The arrival of a "speech director" AI raises important questions about the future of the voice acting industry. While the technology offers unprecedented accessibility for independent creators and small businesses, professional voice actors may face increased competition for "utilitarian" roles, such as corporate training videos or basic narration.
However, many industry experts argue that Gemini 3.1 will serve as a tool for augmentation rather than total replacement. By handling the "bulk" of standard narration, the AI allows human talent to focus on high-stakes performances that require a level of physical presence and unique artistic interpretation that AI cannot yet replicate. Furthermore, the technology opens new doors for accessibility, enabling the visually impaired to access more expressive and less fatiguing audio versions of digital content.
As Gemini 3.1 Flash TTS begins its rollout across Google AI Studio and Vertex AI, the focus shifts to how the global developer community will leverage these tools. From interactive AI tutors that sound genuinely encouraging to localized customer service agents that respect regional linguistic nuances, the potential applications are vast. Google DeepMind has effectively moved the goalposts for AI communication, proving that in the digital age, it is not just what you say, but how you say it.