The current landscape of artificial intelligence interaction is characterized by a fundamental limitation known as "statelessness." In a typical workflow, a developer or researcher uploads a series of files, asks a targeted question, and receives an answer based on that specific context. However, once the session concludes, the model effectively "forgets" the interaction. When the user returns to the same codebase or research collection, the large language model (LLM) must re-read and re-process the entire corpus from scratch. This lack of persistent memory is not only a drain on computational resources but also a significant hurdle for efficiency in complex, long-term projects.
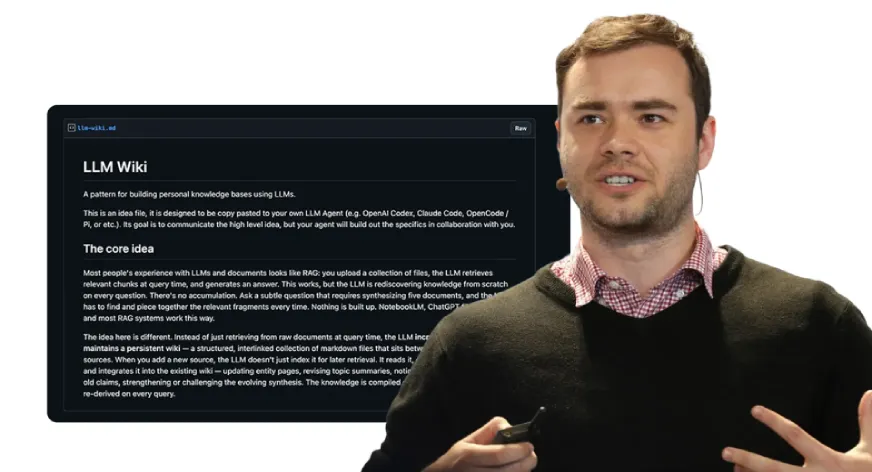
This systemic inefficiency recently gained significant attention when Andrej Karpathy, a founding member of OpenAI and former Director of AI at Tesla, highlighted the gap in modern AI architectures. Karpathy proposed the development of an "LLM Wiki"—a persistent, evolving knowledge layer that grows alongside the user’s work. This concept has rapidly materialized into a functional system known as Graphify. By transforming directories into structured, searchable knowledge graphs, Graphify represents a paradigm shift in how AI assistants interact with large-scale data, moving away from repetitive scanning and toward a model of cumulative intelligence.
The Evolution of AI Context: From RAG to Knowledge Graphs
To understand the significance of Graphify, one must first look at the history of how AI handles large datasets. The industry standard has largely been Retrieval-Augmented Generation (RAG). In a RAG system, documents are broken into "chunks," converted into mathematical vectors, and stored in a database. When a user asks a question, the system finds the most similar chunks and feeds them to the LLM. While effective for simple queries, RAG often struggles with "global" understanding—for example, explaining the overall architecture of a software system or tracing the relationship between two seemingly unrelated modules.
Graphify addresses these shortcomings by moving beyond simple vector similarity. Instead of treating a codebase as a collection of isolated text snippets, it builds a high-fidelity map of connections. This approach aligns with Karpathy’s vision of a structured memory layer that allows an AI to "know" a project rather than just "searching" it. The transition from raw data to structured knowledge graphs marks a new era in AI-assisted engineering, where the tool understands hierarchy, logic, and intent.
Technical Architecture: A Two-Phase Execution Model
The Graphify system operates through a sophisticated two-phase process designed to maximize accuracy while minimizing costs and privacy risks. Unlike many AI tools that send all data to the cloud immediately, Graphify begins with a localized, privacy-first approach.
Phase 1: Local Code Structure Extraction
The first phase utilizes "tree-sitter," an incremental parsing library that builds concrete syntax trees for source files. This process is entirely local and does not involve an LLM. By analyzing the code directly on the user’s machine, Graphify identifies classes, functions, imports, call graphs, and docstrings. This phase also captures "rationale comments"—the "why" behind the code—which are often lost in standard documentation.
The advantages of this local-first phase are threefold:
- Speed: Local parsing is orders of magnitude faster than cloud-based LLM processing.
- Accuracy: Deterministic parsing ensures that the structural relationships (e.g., which function calls which) are 100% accurate.
- Privacy: No sensitive code is transmitted to external servers during the initial mapping phase.
Phase 2: Multimodal Semantic Analysis
Once the structural skeleton is built, Graphify initiates its second phase using Claude-powered subagents. These agents process unstructured content, including PDFs, Markdown files, and even images. This is where the "semantic" layer is added. The subagents extract high-level concepts and design rationales, linking them to the code structure identified in Phase 1.
The culmination of these phases is a unified NetworkX graph. To organize this data, Graphify employs the Leiden community detection algorithm. Unlike traditional methods that require expensive vector embeddings, Leiden is a graph-topology-based method. It clusters related items based on the actual density of their connections within the graph. This ensures that the resulting "communities" of knowledge reflect the logical organization of the project rather than just linguistic similarity.
Performance Metrics and Token Efficiency
One of the most compelling arguments for the adoption of Graphify is its impact on operational costs. In a benchmark study involving a mixed corpus of Andrej Karpathy’s public repositories, academic research papers, and technical diagrams, Graphify demonstrated a 71.5x reduction in token usage per query.
In a standard AI workflow, a developer might need to send 50,000 tokens of context to an LLM to get a reliable answer about a complex system. With Graphify, the AI assistant refers to the pre-built GRAPH_REPORT.md and navigates the graph structure to find the specific nodes required. This targeted approach allows the system to provide the same—or better—answers using only a fraction of the data. For enterprise-level applications where AI API costs can reach thousands of dollars per month, a 70-fold increase in efficiency represents a transformative economic shift.
Implementation and Workflow Integration
Graphify is designed to integrate seamlessly into existing AI coding environments. It currently supports a wide range of platforms, including Claude Code, Cursor, Codex, and the Gemini CLI. The installation is streamlined into a single command: pip install graphify && graphify install.
Once installed, users can initialize the system within their AI assistant using the /graphify command. The system generates a graphify-out/ directory containing four critical components:
- graph.json: The raw data structure of the knowledge graph.
- graph.png: A visual representation of the project’s architecture.
- GRAPH_REPORT.md: A high-level summary that serves as the AI’s "map" of the codebase.
- SHA256 Cache: A tracking mechanism that ensures only changed files are re-processed in future sessions.
The system also introduces a "Confidence Level" tagging system. Every relationship identified in the graph is labeled as "Found" (explicitly stated in code), "High," "Medium," or "Low" (inferred by the AI). This transparency allows developers to verify the AI’s logic and distinguish between hard facts and heuristic interpretations.
Always-On Mode: Redefining the Assistant’s Behavior
Perhaps the most significant feature for power users is the "Always-On" mode. By running graphify claude install, the system modifies the environment of the AI assistant. It creates a CLAUDE.md file that instructs the model to consult the graph report before responding to architectural questions. Furthermore, it injects a "PreToolUse" hook into the system settings.
This modification fundamentally changes the assistant’s behavior. Instead of using "Glob" or "Grep" to search for strings across hundreds of files, the assistant uses the knowledge graph to navigate directly to the relevant logic. This "structure-aware" navigation results in faster response times and eliminates the "hallucinations" that often occur when an AI loses track of context in a large file tree.
Multimodal and Research Support
While its roots are in coding, Graphify’s support for diverse file types makes it a potent tool for academic and corporate research. Beyond standard .py, .js, and .cpp files, Graphify can process:
- Document Formats: PDF, DOCX, PPTX, and XLSX.
- Web and Data: HTML, XML, and JSON.
- Rich Media: Images containing diagrams or handwritten notes.
By dropping a folder of mixed research materials into Graphify, a user can create a unified knowledge base where a Python script’s logic is linked to a mathematical formula in a PDF whitepaper and a project timeline in a PowerPoint deck. This cross-pollination of data types is essential for modern R&D teams who must synthesize information from disparate sources.
Industry Implications and the Future of AI Memory
The release of Graphify and the realization of the LLM Wiki concept signal a broader trend in the AI industry: the move toward persistent, agentic memory. As LLM context windows continue to grow, the "brute force" method of feeding more data into a prompt is hitting a ceiling of diminishing returns due to latency and cost. Graphify provides a sophisticated alternative by treating memory as a structured asset rather than a temporary buffer.
Industry analysts suggest that this approach could significantly reduce "technical debt" in large organizations. When a new engineer joins a team, they typically spend weeks or months understanding the "tribal knowledge" of a codebase. With a persistent knowledge graph, an AI assistant can act as a permanent repository of that knowledge, explaining not just what the code does, but how every piece fits into the larger ecosystem.
Furthermore, the use of SHA256 caching ensures that the system is sustainable. By only regenerating the parts of the graph that have changed, Graphify avoids the "re-indexing" tax that plagues many traditional search tools. This makes it viable for massive, fast-moving codebases like those found at major tech firms.
Conclusion
Graphify represents a critical step toward making AI assistants truly useful for complex, long-term work. By solving the problem of statelessness and providing a structured memory layer, it fulfills Andrej Karpathy’s vision of an evolving LLM Wiki. For developers and researchers, this means an end to the "groundhog day" cycle of AI interactions. Instead of starting from zero every morning, users can now build upon a foundation of structured insights, turning their AI assistant from a simple chatbot into a deeply informed collaborator. As the technology matures, the integration of knowledge graphs is likely to become a standard requirement for any AI system claiming to handle professional-grade complexity.