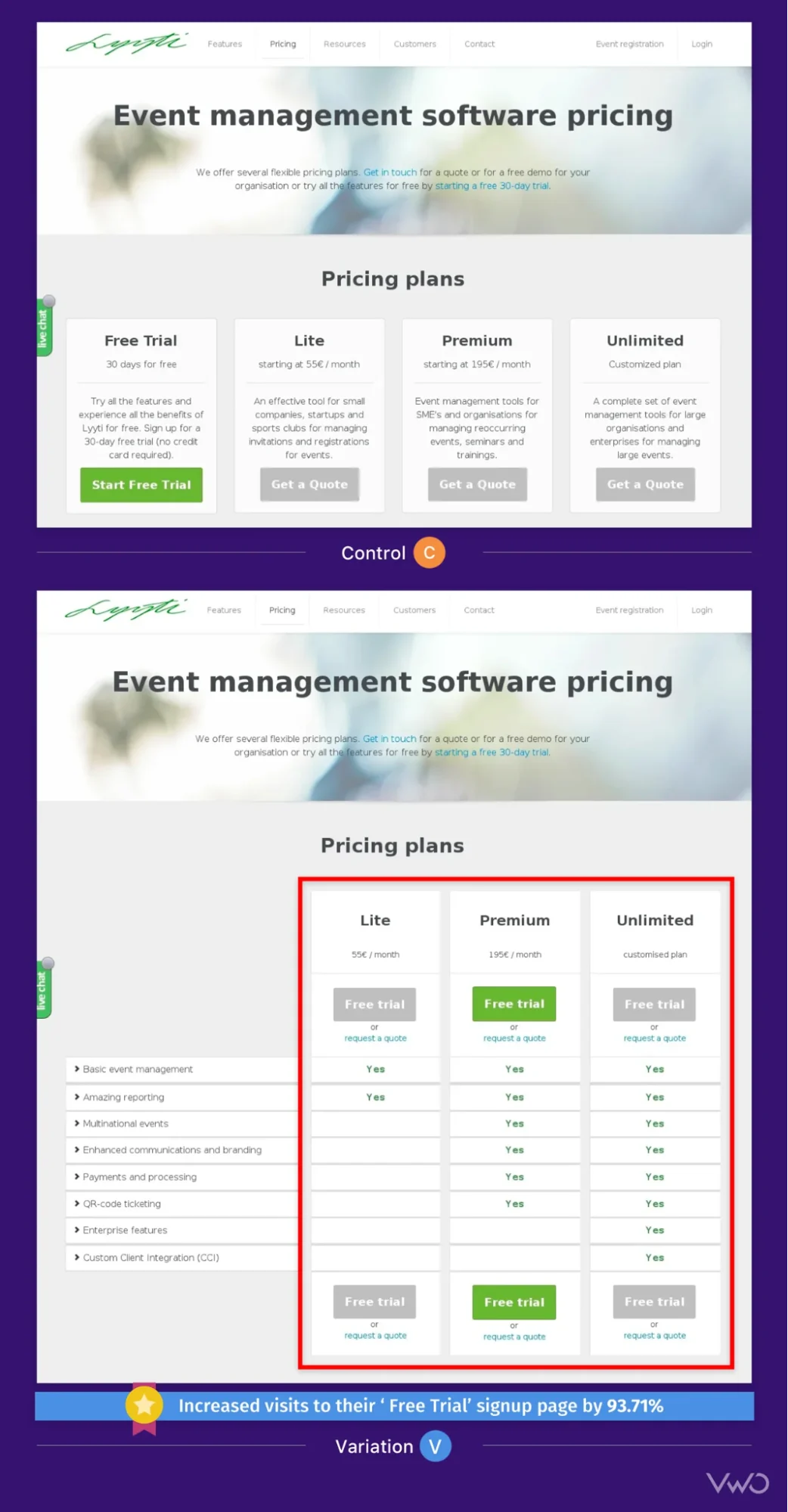
The digital commerce landscape has reached a critical inflection point where the traditional reliance on simple A/B testing is no longer sufficient to drive sustainable growth. While the practice of comparing two versions of a webpage to determine a "winner" remains a staple of conversion rate optimization (CRO), industry experts and high-maturity product teams are sounding the alarm on its limitations. The transition from a "test everything" culture to a strategic experimentation framework marks a significant shift in how modern enterprises approach user experience and revenue generation.
For many organizations, the journey into experimentation begins with a modest success—a headline change that yields a minor uptick in conversions or a button color adjustment that improves click-through rates. These early wins often create a feedback loop where testing becomes the default decision-making tool. However, as digital markets mature, the low-hanging fruit of cosmetic UI tweaks has largely been picked, leaving teams struggling with stagnant results and "winning" tests that fail to translate into long-term profitability.
The Historical Context and the Rise of the A/B Default
A/B testing gained mainstream prominence in the early 2010s, championed by tech giants and reinforced by the emergence of user-friendly experimentation platforms. The narrative was solidified by high-profile success stories, most notably from Microsoft’s Bing team. In a now-legendary experiment, Microsoft engineers tested the way ad headlines were displayed, merging two lines into one longer headline. This seemingly minor adjustment increased the click-through rate significantly, generating an estimated $100 million in additional annual revenue.

Following such successes, experimentation became a cultural norm within Silicon Valley and beyond. Today, Microsoft reportedly runs more than 20,000 controlled experiments annually across its Bing platform alone. This culture was democratized by platforms like FigPii and Optimizely, which made it possible for marketing teams to launch tests without deep expertise in statistics or data science. Consequently, industry data reveals that 77% of all digital experiments are simple A/B tests involving only two variants. This "simplicity bias" has led many teams to ignore more complex multivariate or multi-treatment designs that could yield deeper insights.
The Statistical Reality and the Problem of Scale
One of the most significant challenges facing modern CRO programs is the lack of statistical power. For an A/B test to be valid, it requires a sufficient volume of traffic and conversions to distinguish a real behavioral shift from random noise. To detect a small but meaningful lift of 1% to 2% with high confidence, a website typically needs hundreds of thousands of visitors per variant.
For the vast majority of e-commerce brands, this level of traffic is unavailable. Even mid-market companies generating millions of sessions per month often find that running a statistically significant test takes six to twelve weeks. This delay slows the pace of innovation and often leads to three common failure modes:
- Underpowered Tests: Launching tests that have no realistic chance of reaching significance.
- Peaking: Stopping tests early as soon as a "winner" appears, which often results in false positives.
- The "Flat" Result: Teams spend months testing minor variations only to find no detectable difference, leading to "testing fatigue" within the organization.
The Survivorship Bias in Conversion Data
A fundamental flaw in over-relying on A/B testing is that it focuses exclusively on the "what" rather than the "why." A test result might indicate that Variant B outperformed Variant A, but it offers no explanation for the underlying user motivation. This creates a strategic blind spot often compared to the survivorship bias observed in World War II.
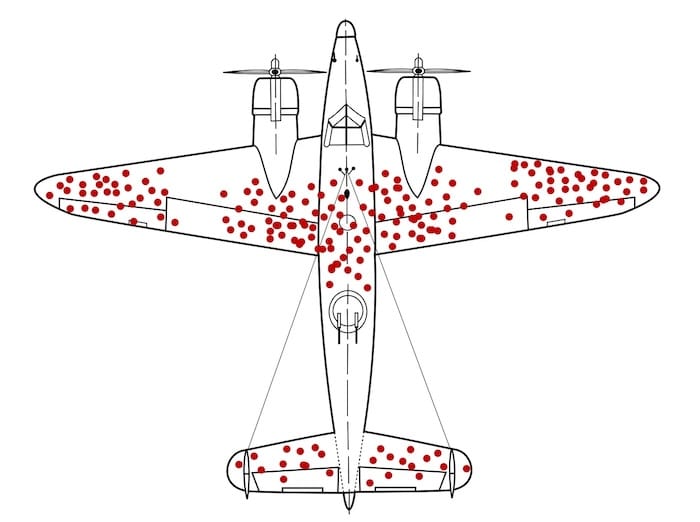
During the war, the military analyzed returning aircraft to determine where to add armor, noting that the fuselage was frequently riddled with bullet holes while the engines remained untouched. It was statistician Abraham Wald who realized the flaw: they were only looking at the planes that survived. The planes hit in the engine never made it back to be analyzed. Similarly, A/B tests primarily show the behavior of users who "survived" the funnel. They fail to capture the frustrations of those who dropped off entirely, leaving teams to optimize for the visible "bullet holes" rather than addressing the structural vulnerabilities that cause users to exit the site.
Short-Term Wins vs. Long-Term Business Health
Perhaps the most dangerous aspect of the A/B testing trap is the misalignment between short-term metrics and long-term business outcomes. Most experiments focus on immediate actions: clicks, add-to-carts, or single-session purchases. However, these metrics can be misleading indicators of a company’s overall health.
A common example is the "Choice Overload" effect. In a famous study involving gourmet jam, researchers found that while a display with 24 varieties of jam attracted more attention, a display with only six varieties led to significantly higher sales. In a modern digital context, a variant that increases engagement or clicks might actually confuse the customer, leading to a higher return rate or lower customer lifetime value (LTV) in the following months. High-maturity teams are now shifting their focus from "conversion rate" to "profit per visitor" and "retention-adjusted revenue," recognizing that a short-term "win" that hurts brand trust is a long-term loss.
The High-Maturity Toolkit: Beyond the Binary
To overcome these limitations, leading organizations are adopting a broader experimentation toolkit. This transition involves moving away from binary A/B tests toward more sophisticated methods tailored to specific business questions.

1. Sequential and Switchback Testing
In environments where users interact with one another or where supply and demand are linked (such as marketplaces or delivery apps), traditional A/B splits can produce "interference." In these cases, teams use switchback testing—alternating between versions over specific time intervals—to get a cleaner read on performance.
2. Holdout Groups and Quasi-Experiments
To measure the long-term impact of a new feature or pricing model, mature teams utilize holdout groups. By keeping a small percentage of the audience on the "old" version for several months, the company can track the true incremental value of a change over time, accounting for seasonal trends and repeat purchase behavior.
3. Research-Driven Hypotheses
The quality of an experiment is directly tied to the quality of the hypothesis. High-maturity teams do not pull ideas from a vacuum; they ground their tests in qualitative and quantitative research. This includes:
- Session Recordings: Observing where users hesitate or encounter errors.
- Customer Support Logs: Identifying recurring complaints or points of confusion.
- Heuristic Evaluations: Assessing the clarity and value proposition of a page against industry standards.
A robust hypothesis follows a strict logical structure: "Because [Evidence], we believe [User Problem] exists, so we will [Change], and we expect [Metric] to improve." This ensures that every test, regardless of the outcome, provides a learning opportunity for the business.
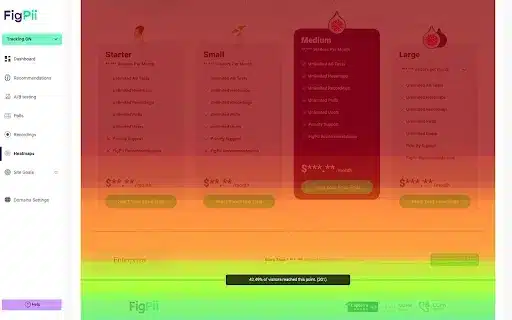
Strategic Implications for the Future of Commerce
The shift toward a more holistic experimentation framework has profound implications for how digital businesses are structured. It requires a departure from "siloed" testing—where the marketing team tests headlines while the product team tests features—toward a unified growth strategy.
Industry analysts suggest that the next frontier of experimentation will be driven by artificial intelligence and machine learning, allowing for "multi-armed bandit" testing. Unlike traditional A/B tests, bandit algorithms automatically shift traffic toward the winning variant in real-time, minimizing the "opportunity cost" of showing a sub-optimal version to users. However, even with AI, the human element of strategic questioning remains paramount.
As digital competition intensifies, the companies that succeed will not be those that run the most tests, but those that run the right tests. By focusing on "big levers"—such as pricing models, value propositions, and information architecture—rather than cosmetic UI tweaks, organizations can move past the plateau of small wins and achieve meaningful, compounding growth.
The era of A/B testing as a standalone solution is ending. In its place is a more rigorous, evidence-based discipline that views experimentation not as a series of isolated events, but as a continuous process of business discovery. For teams looking to reach this level of maturity, the path forward involves embracing complexity, prioritizing long-term metrics, and never losing sight of the human "why" behind the digital data.