
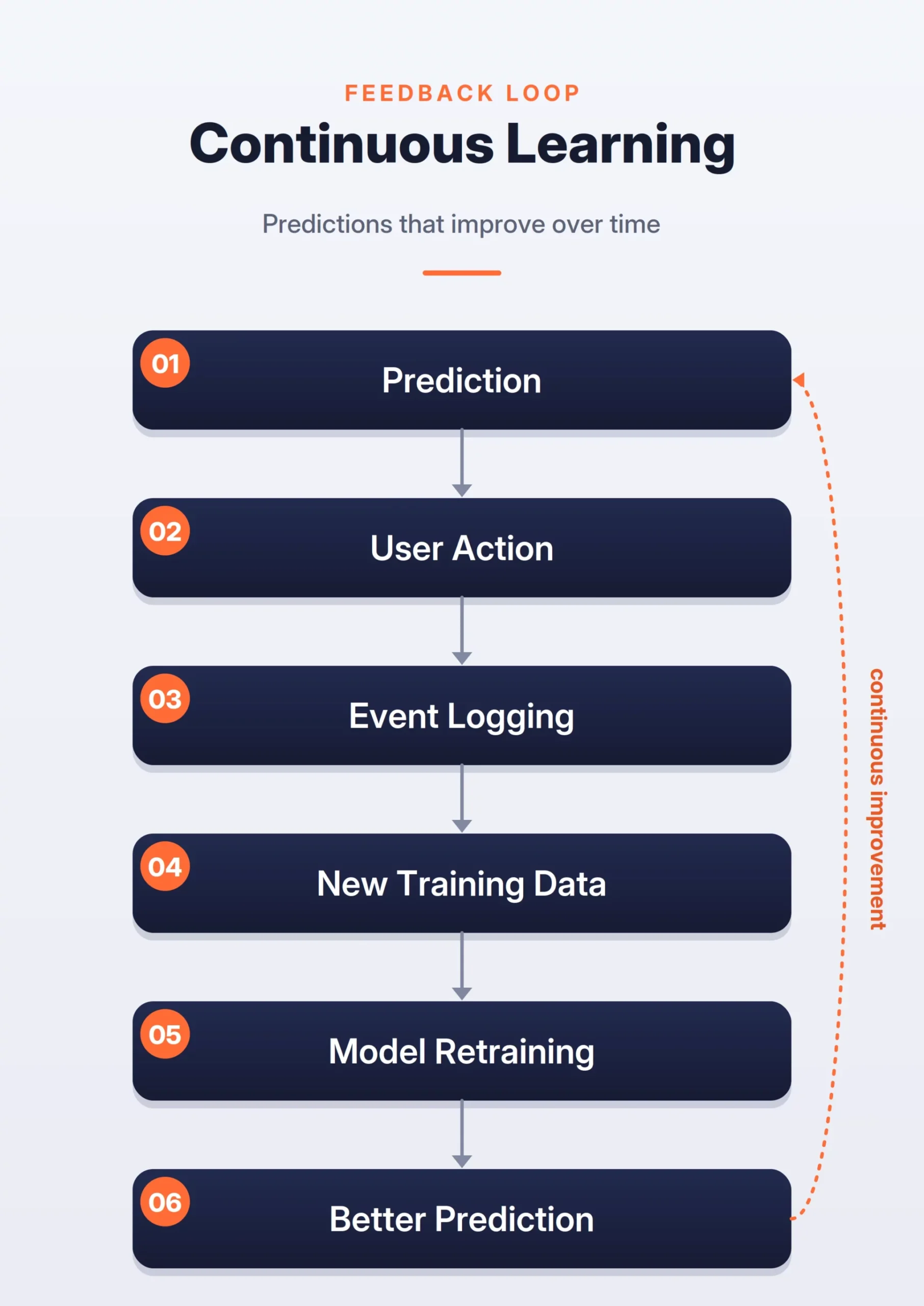
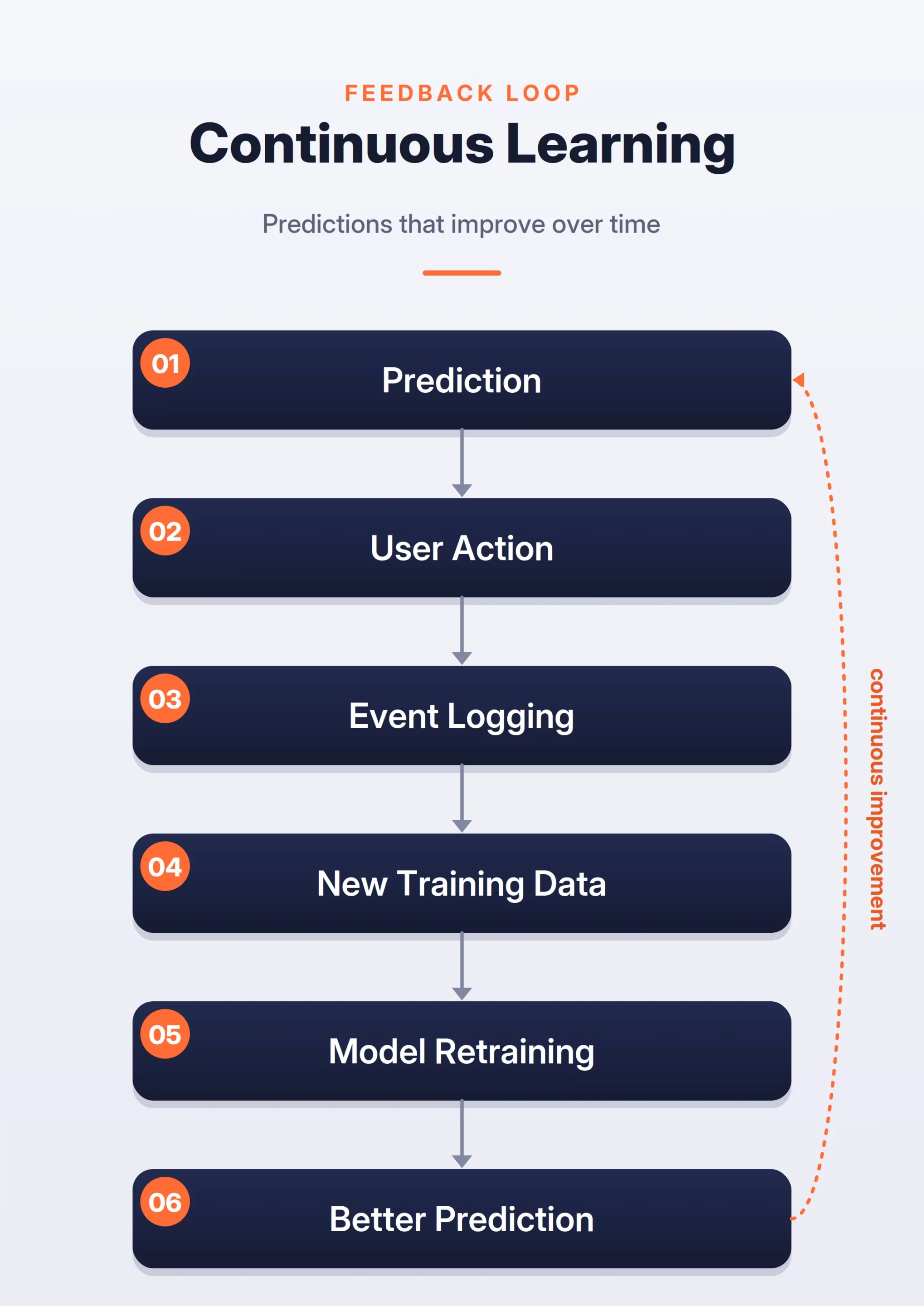
The landscape of technical recruitment in the artificial intelligence sector has undergone a fundamental shift, moving away from purely algorithmic coding challenges toward complex Machine Learning (ML) system design evaluations. In contemporary high-stakes interviews at organizations such as Google, Meta, and Amazon, the ability to select a specific model is regarded as merely a prerequisite. Candidates are now expected to demonstrate a holistic understanding of the entire ML lifecycle, including data ingestion pipelines, feature engineering at scale, low-latency inference, and automated feedback loops. As organizations increasingly integrate AI into core product offerings, the emphasis has transitioned from theoretical model performance to the practical reliability and scalability of the systems supporting those models.

The Architectural Framework of Modern ML Systems
Success in an ML system design interview requires a structured approach that transcends the “black box” of the model. Expert practitioners suggest beginning with a clear definition of the product goal. Every enterprise ML system is designed to facilitate a specific decision—whether that involves selecting the most relevant post for a social media user, identifying a fraudulent transaction in milliseconds, or optimizing the price of a ride-share service during peak hours.
Once the objective is established, defining success becomes the next critical step. Professional architectures are evaluated against three distinct tiers of metrics. First, model metrics, such as Precision, Recall, and F1-score, provide a technical baseline. Second, product metrics, including Click-Through Rate (CTR) and Dwell Time, measure user engagement. Finally, business metrics, such as Revenue per Mille (RPM) and Customer Lifetime Value (CLV), determine the system’s economic viability. A common pitfall for candidates is focusing solely on model accuracy while ignoring the business implications of false positives or high latency.
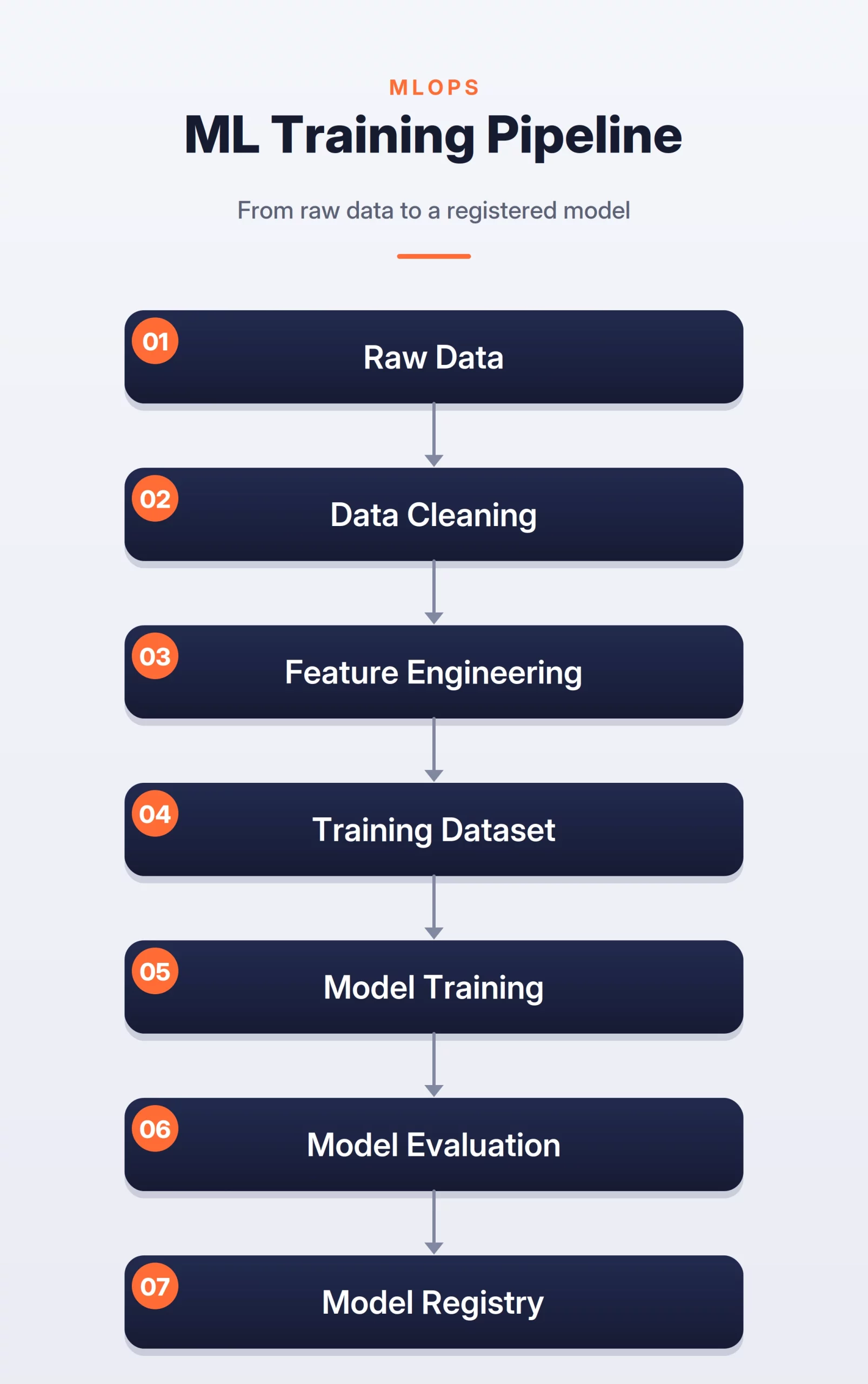
From an engineering perspective, a robust ML system is typically divided into three primary pathways:
- The Offline Path: This batch-oriented environment is dedicated to historical data processing, feature engineering, and model training. The focus here is on data integrity, reproducibility, and the ability to handle petabyte-scale datasets using frameworks like Apache Spark.
- The Online Path: This is the “live” environment where the model serves predictions to users. Here, the primary constraints are latency and availability. Systems must often respond in under 100 milliseconds, necessitating efficient feature retrieval from low-latency stores like Redis or Cassandra.
- The Feedback Loop: This critical component closes the circle by capturing user interactions with the model’s predictions. This data is logged and funneled back into the offline path for continuous retraining, allowing the system to adapt to shifting user behaviors and data drift.
1. Personalized Feed Ranking Architectures
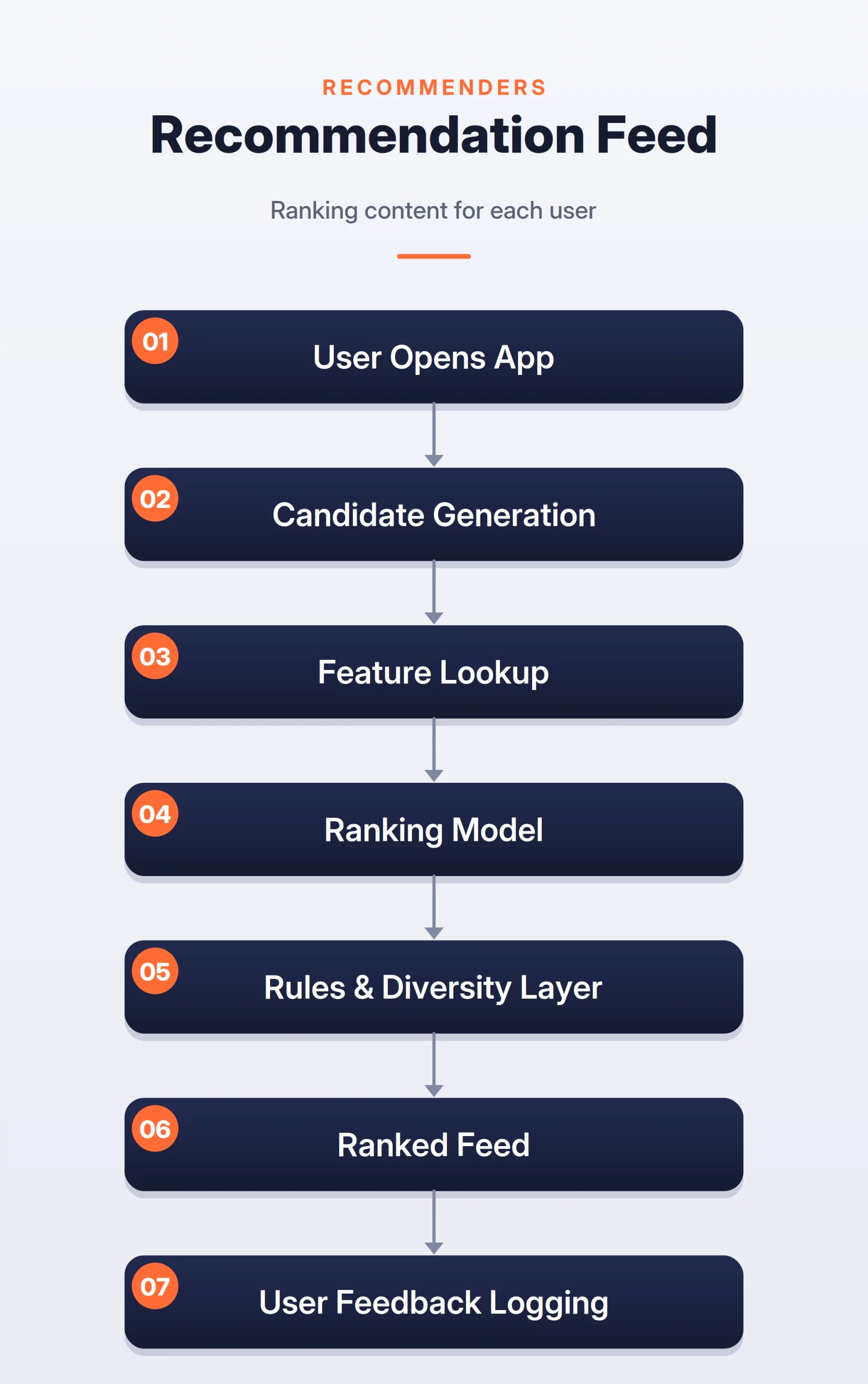
Designing a feed ranking system for platforms like Instagram or TikTok involves managing a massive candidate pool. With millions of potential posts available, scoring every item in real-time is computationally impossible. Therefore, modern architectures utilize a multi-stage funnel.

The process begins with “Candidate Generation,” where lightweight models (often based on collaborative filtering or two-tower embeddings) narrow down millions of items to a few hundred. This is followed by “Ranking,” where a high-precision deep neural network or Gradient Boosted Decision Tree (GBDT) scores the remaining candidates based on rich features like user history, post popularity, and contextual relevance. The final stage involves “Re-ranking,” where business logic is applied to ensure content diversity and safety, preventing the user from seeing repetitive content.
2. Real-Time Ad Click-Through Rate (CTR) Prediction
Ad serving systems represent the financial backbone of the modern internet. Unlike content ranking, ad systems must balance three competing interests: user experience, advertiser return on investment (ROI), and platform revenue.
The core of this system is the CTR prediction model, which estimates the probability of a click. However, the final selection involves an “Auction” mechanism. The system calculates an Expected Value (e.g., Bid Price × Predicted CTR) to determine which ad wins the slot. Key challenges in this domain include “Data Sparsity”—where most users never click on most ads—and “Exploration vs. Exploitation,” ensuring new ads get enough exposure to gather data without sacrificing immediate revenue.
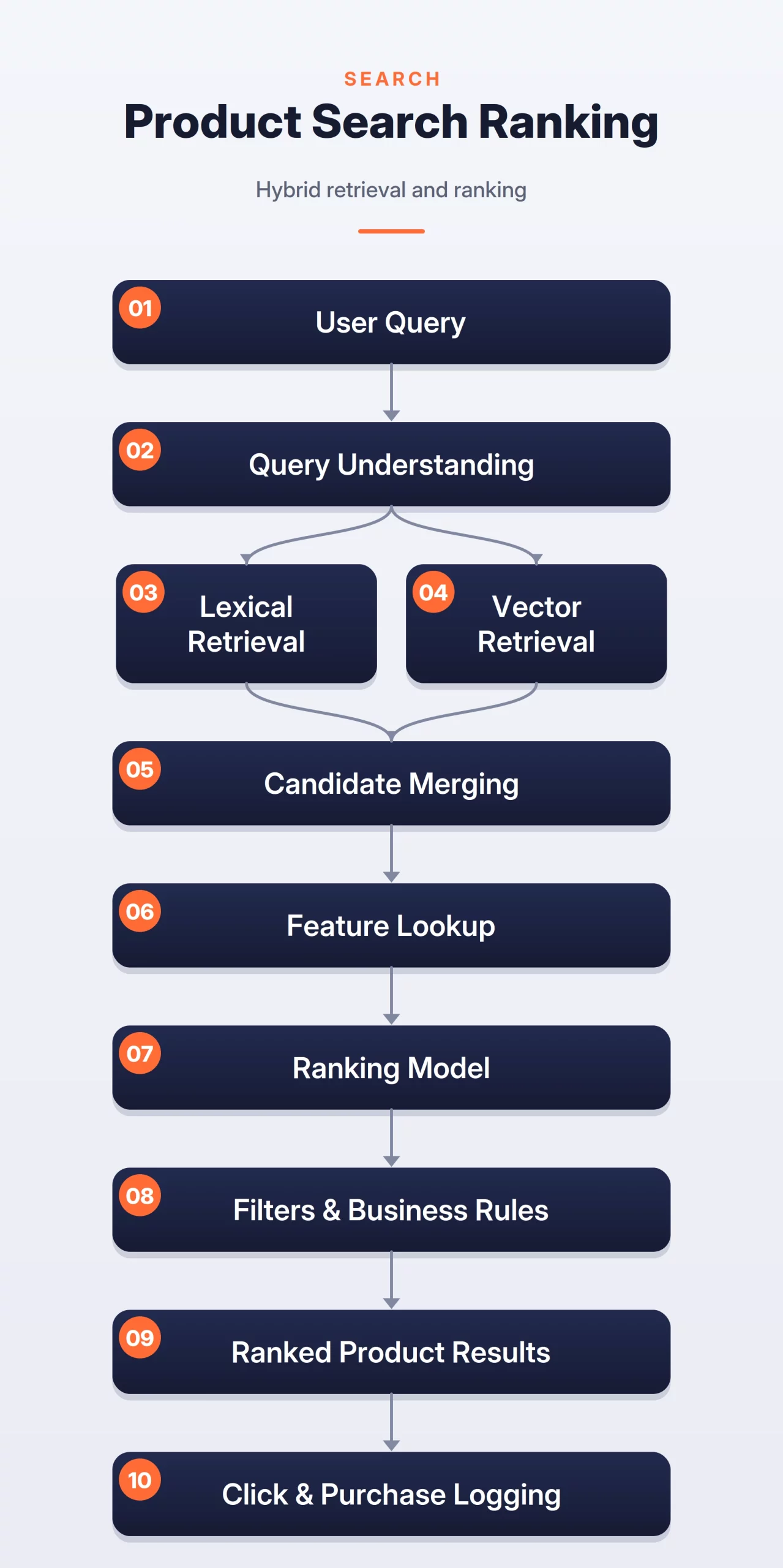
3. E-commerce Search and Semantic Retrieval
The evolution of e-commerce search has moved from simple keyword matching (lexical search) to understanding user intent (semantic search). A robust search ranking system must handle “Long-tail Queries” where the exact words may not exist in the product description.
State-of-the-art systems employ “Hybrid Retrieval,” combining traditional BM25 scoring with vector-based retrieval using models like BERT. This allows the system to understand that a query for “warm winter footwear” should return “thermal boots.” Industry data suggests that improving search relevance by even 1% can result in millions of dollars in incremental GMV (Gross Merchandise Volume) for large-scale retailers.
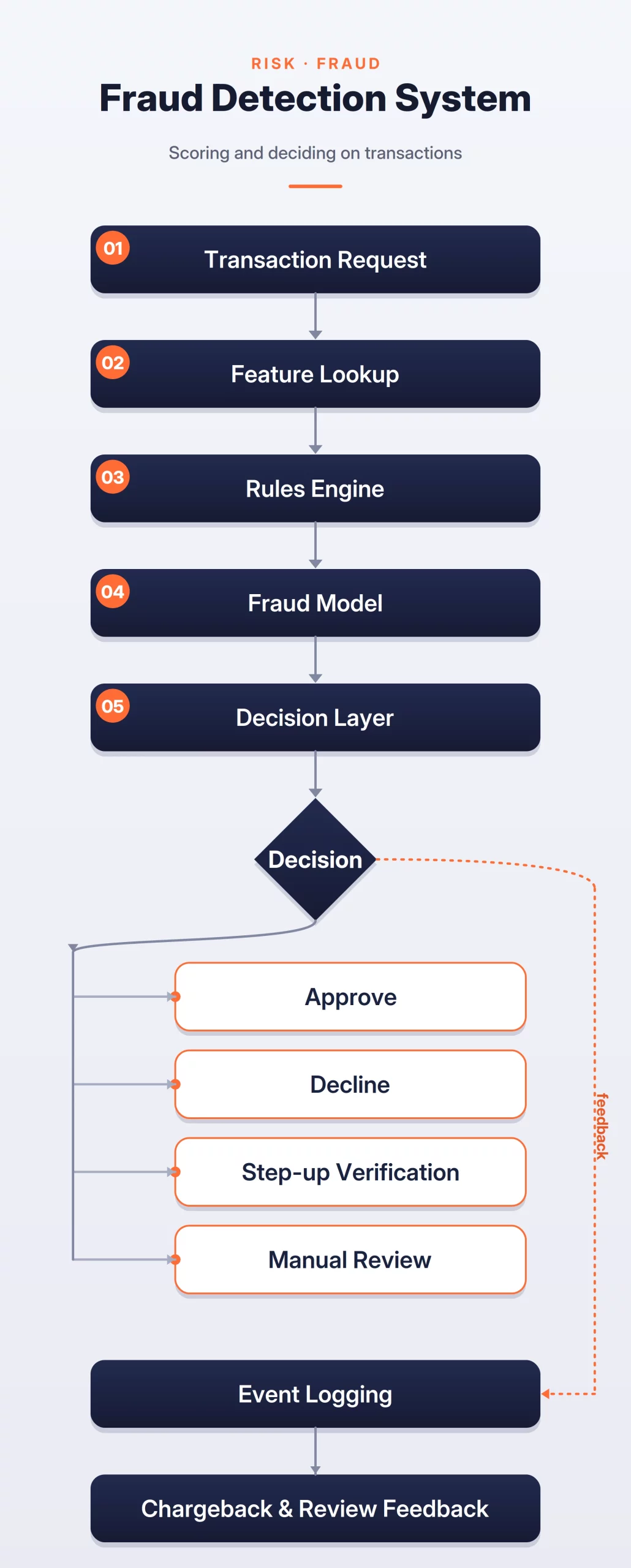
4. High-Stakes Fraud Detection Systems
Fraud detection is a classic “cat-and-mouse” game characterized by extreme class imbalance; legitimate transactions outnumber fraudulent ones by thousands to one. The architectural challenge here is minimizing “False Positives” to avoid blocking genuine customers, which causes “Customer Friction.”
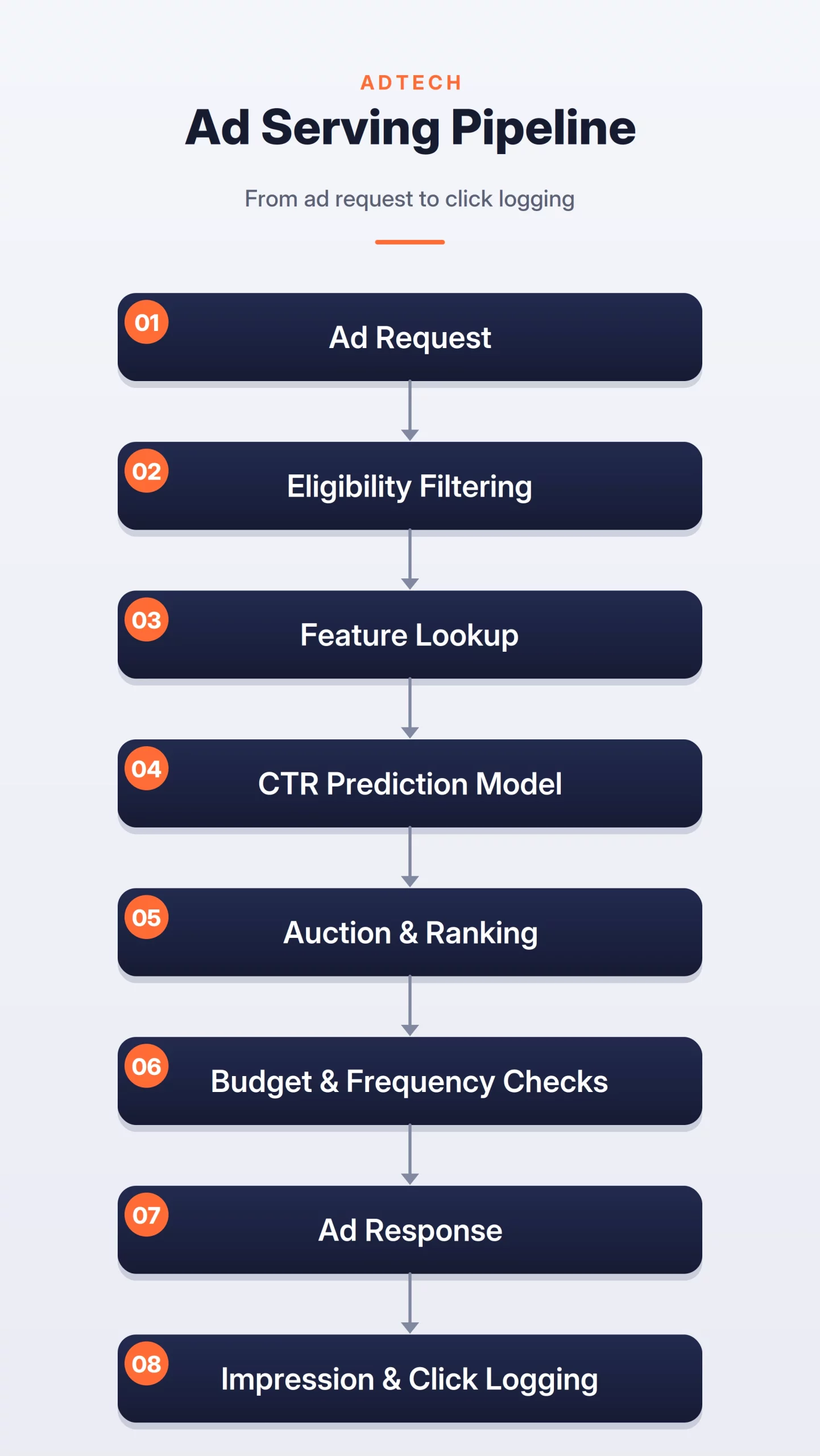
These systems often utilize a “Rules + ML” approach. Hard-coded rules provide an immediate defense against known attack vectors, while ML models detect subtle, evolving patterns. Features often include “Velocity Signals,” such as the number of transactions from a specific IP address in the last 60 seconds. Because fraud labels are often delayed (e.g., a chargeback might occur 30 days later), the system must be designed to handle asynchronous label updates for retraining.
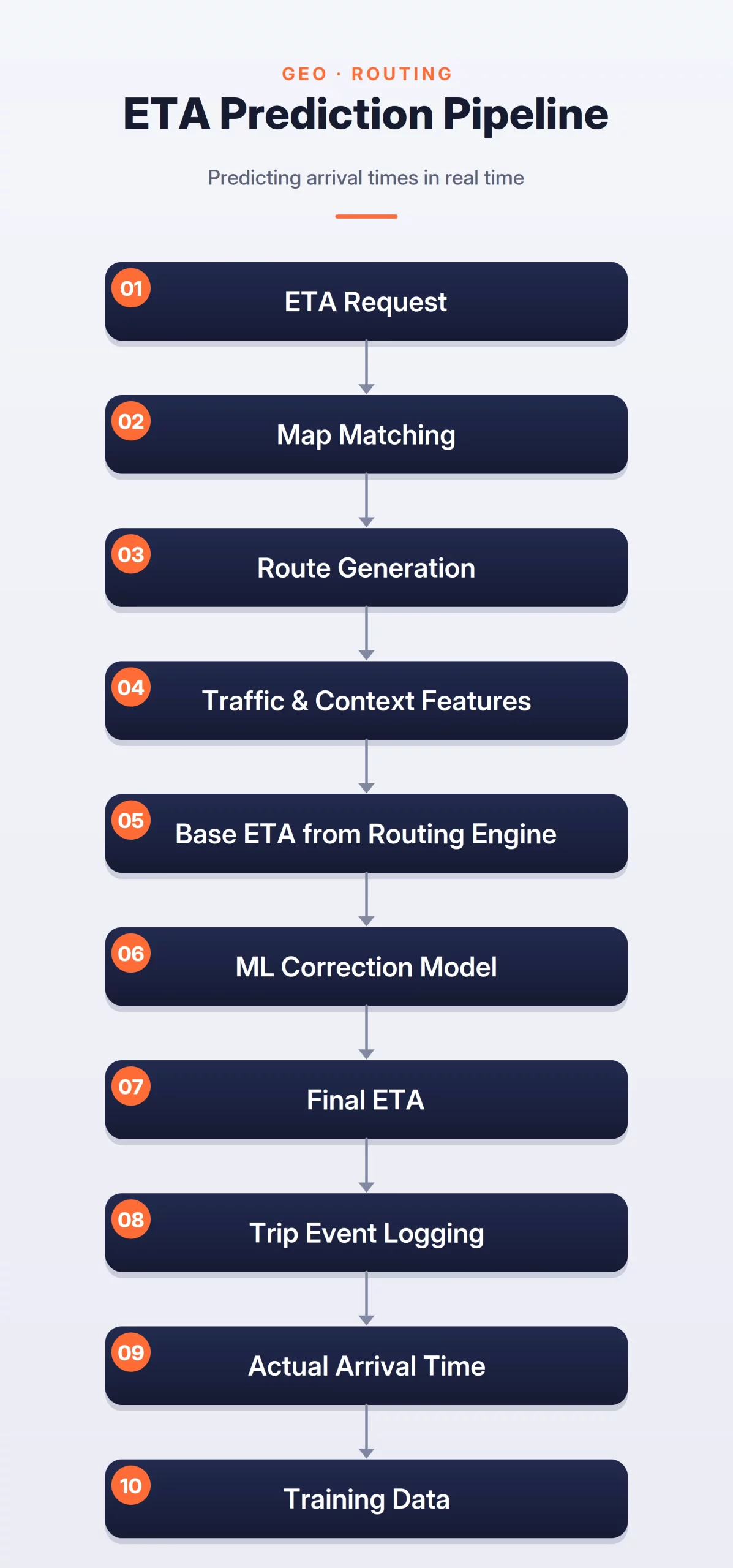
5. Estimated Time of Arrival (ETA) for Logistics
In ride-sharing and delivery, ETA accuracy is a primary driver of customer satisfaction. Modern ETA systems typically build upon a base routing engine (which calculates the shortest path via a graph of road segments) and use ML to predict the “Residual Error.”
The ML model accounts for real-time variables like weather, holiday traffic, and driver-specific behavior. Graph Neural Networks (GNNs) have recently gained popularity in this space due to their ability to model the spatial relationships between different road segments. A key trade-off in ETA design is “Accuracy vs. Stability”—users find it frustrating if an arrival time fluctuates wildly every few seconds.
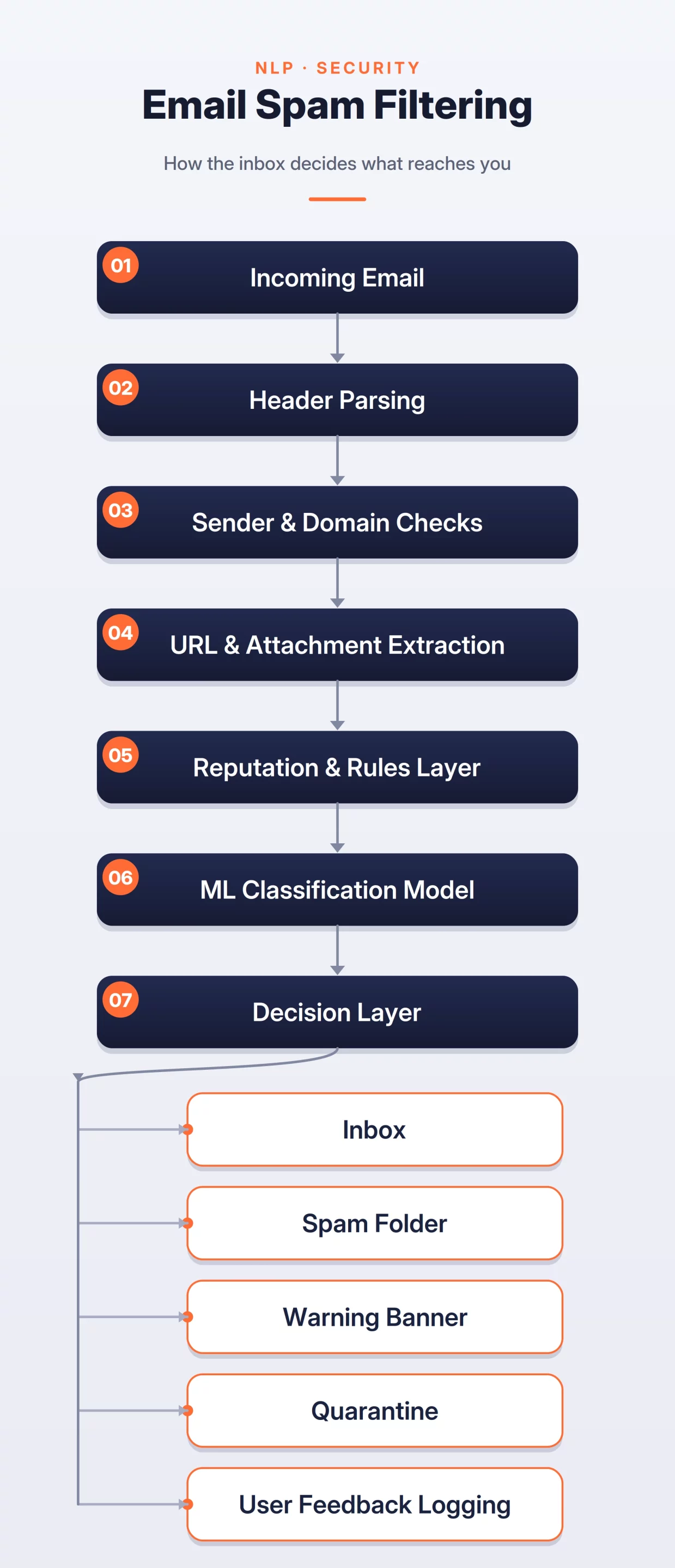
6. Enterprise-Grade Spam and Phishing Mitigation
Security-focused ML systems, such as spam filters, must operate at a scale where “False Positives” are nearly unacceptable—moving a critical business email to the spam folder can have dire consequences.
Beyond Natural Language Processing (NLP) of the email body, these systems rely heavily on “Reputation Signals” (sender IP history, domain age) and “Authentication Protocols” (SPF, DKIM, DMARC). Modern phishing attacks often use “Look-alike Domains” or obfuscated URLs, requiring the system to perform real-time URL expansion and sandboxing of attachments.
7. Visual Defect Detection in Manufacturing
Computer Vision (CV) has revolutionized quality control on factory floors. Designing a visual defect detection system requires a shift toward “Edge Computing.” Because manufacturing lines move at high speeds, sending high-resolution images to the cloud for inference introduces intolerable latency.
Architectures typically involve deploying lightweight models (like YOLO or MobileNet) on edge devices (like NVIDIA Jetson). These systems must also account for “Environmental Drift,” where changes in factory lighting or camera positioning can degrade model performance. The inclusion of a “Human-in-the-loop” review process is essential for validating uncertain cases and generating high-quality labels for model refinement.
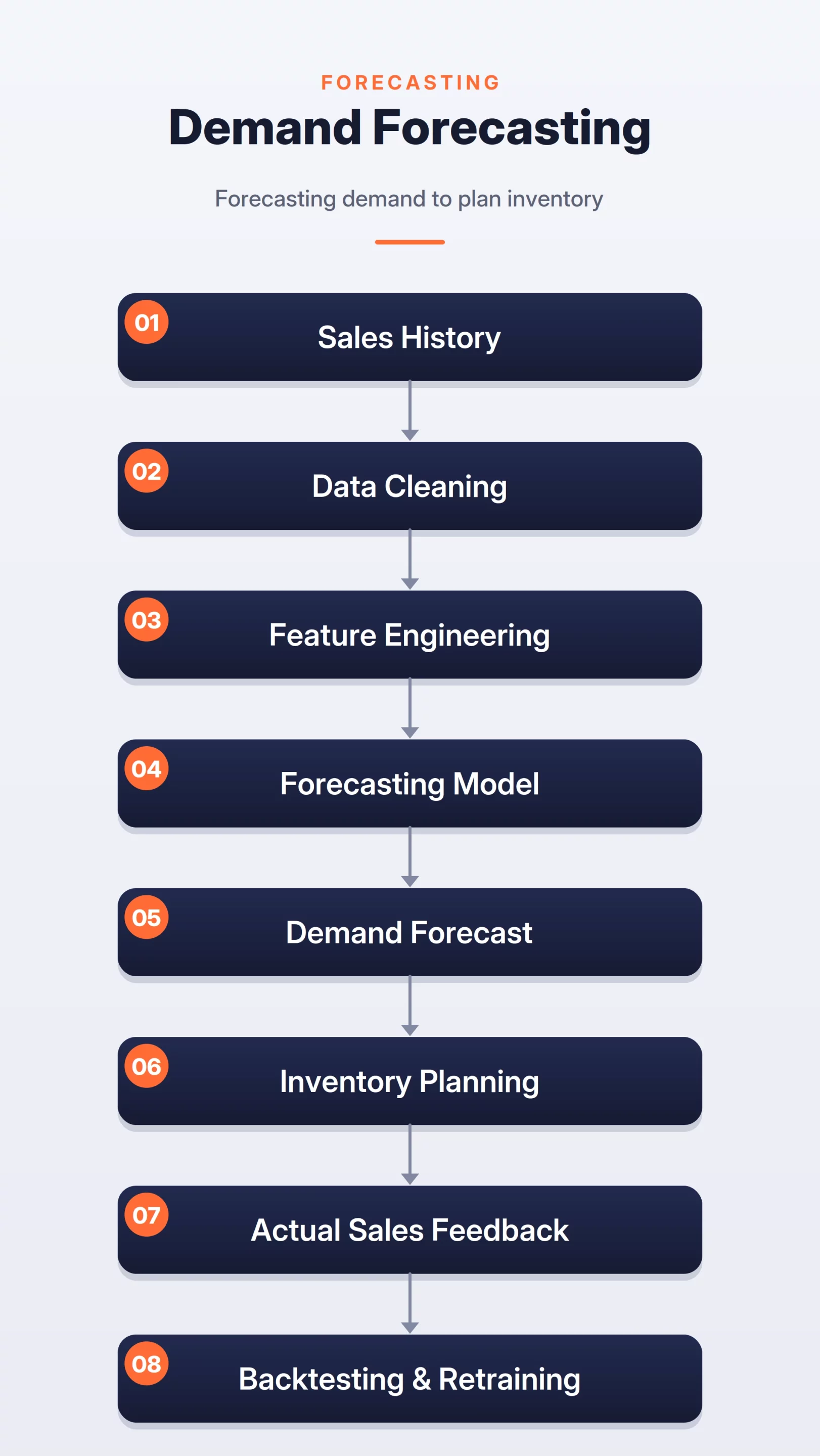
8. Demand Forecasting for Supply Chain Optimization
Demand forecasting systems are essential for inventory management. The objective is to balance the cost of “Stockouts” (lost sales) against the cost of “Overstocking” (wastage and storage fees).
Forecasting models must handle “Seasonality,” “Promotions,” and “Cannibalization” (where a discount on one product reduces sales of another). A critical concept in this domain is “Censored Demand”—if a product is out of stock, the sales data reflects zero, but the actual demand was likely higher. Advanced systems use “Probabilistic Forecasting” to provide a range of possible outcomes, allowing supply chain managers to plan for various risk levels.
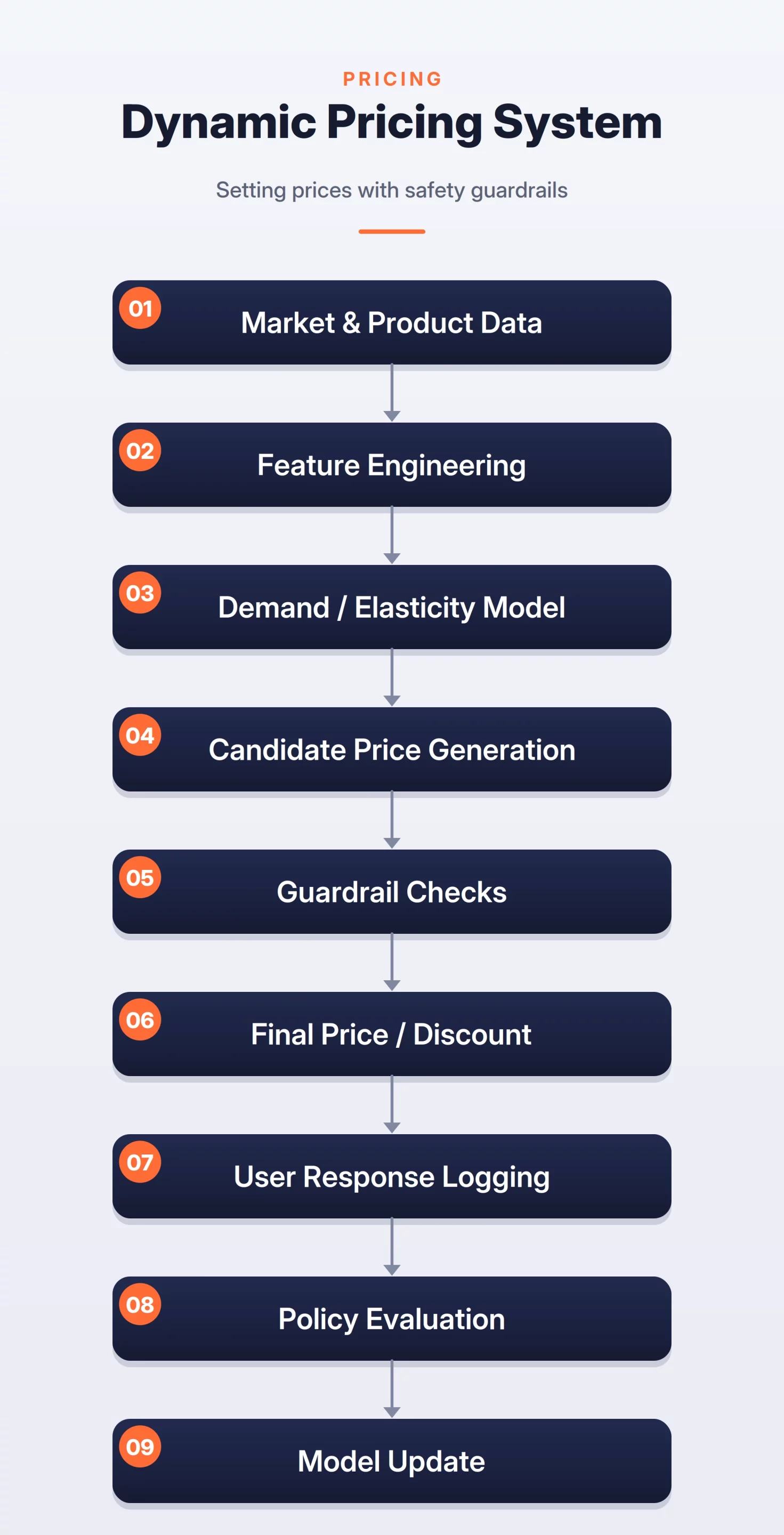
9. Dynamic Pricing and Revenue Management
Dynamic pricing systems, used by airlines and ride-sharing apps, adjust prices in real-time based on supply and demand. The design must incorporate “Guardrails” to ensure prices remain within legal and ethical boundaries, preventing “Price Gouging” during emergencies.
While Reinforcement Learning (RL) is a theoretically ideal fit for pricing, most production systems start with “Contextual Bandits.” This approach allows for controlled experimentation to find the optimal price point while minimizing the risk of a “Runaway Model” that sets nonsensical prices. Fairness metrics are increasingly important here to ensure the system does not inadvertently discriminate against specific user segments.
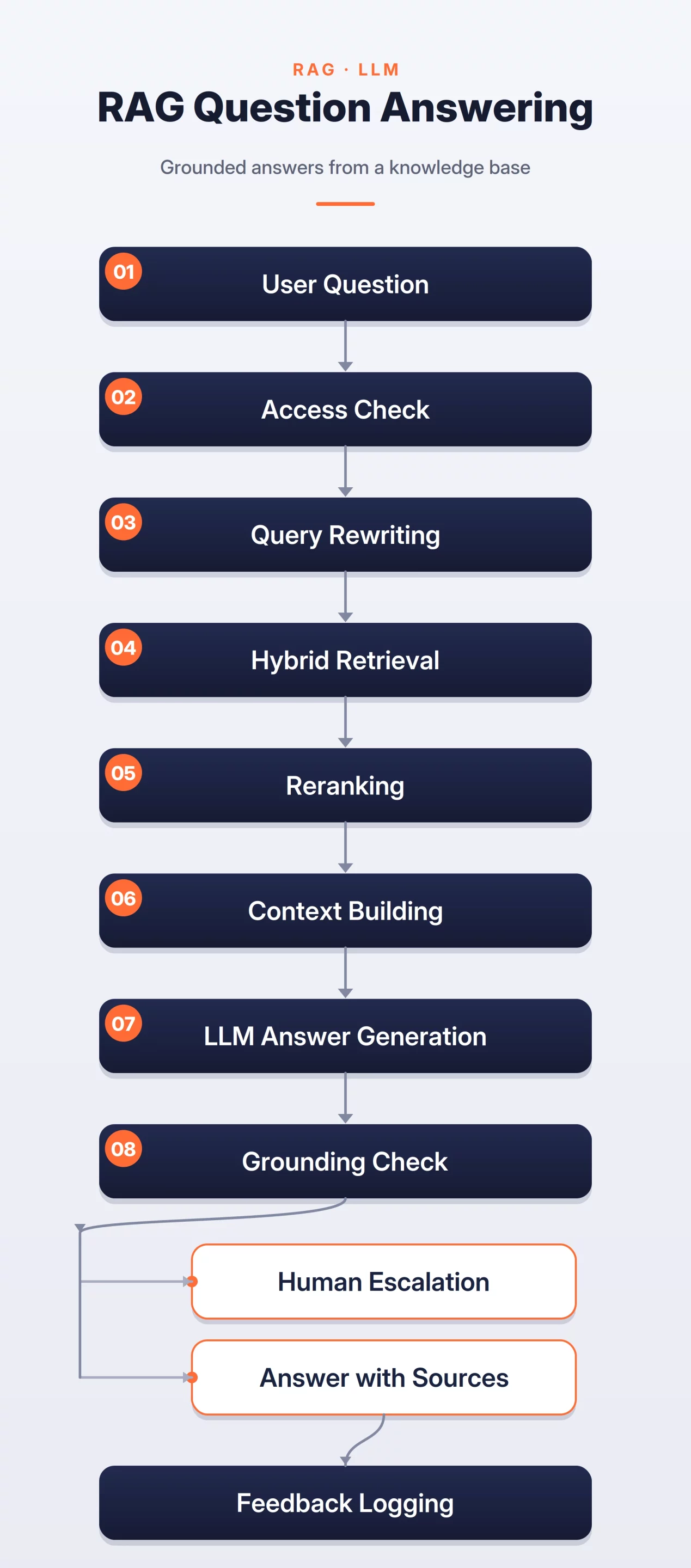
10. RAG-Based Customer Support Assistants
The rise of Large Language Models (LLMs) has introduced Retrieval-Augmented Generation (RAG) as the standard for automated customer support. Instead of relying on the LLM’s internal knowledge—which may be outdated or prone to hallucinations—RAG systems retrieve relevant snippets from a company’s internal documentation to ground the response.
The architecture involves a “Vector Database” (like Pinecone or Milvus) to store document embeddings. When a user asks a question, the system performs a similarity search, feeds the results into the LLM prompt, and asks the model to generate an answer based only on the provided context. Key metrics for RAG systems include “Faithfulness” (does the answer match the source?) and “Relevance” (does the answer address the user’s query?).
Evolution and Industry Implications
The transition toward these complex system designs reflects the maturation of the AI industry. Historically, ML was a niche research field; today, it is a core engineering discipline. Hiring managers now report that the most successful candidates are those who view ML as a component of a larger software ecosystem.
The implications of these designs extend beyond the interview room. As these systems become more autonomous, the industry is seeing a heightened focus on “Observability” and “Explainability.” Engineers are now tasked with building “Model Dashboards” that track not just accuracy, but also feature importance and data drift in real-time.
Conclusion: The Production-Ready Checklist
To excel in an ML system design evaluation, one must move beyond the model and consider the following “Production-Ready” checklist:
- Scalability: Can the system handle a 10x increase in traffic?
- Latency: Are the feature lookups and model inferences within the p99 requirements?
- Data Integrity: How does the system handle missing features or corrupted data streams?
- Privacy and Safety: Does the design comply with GDPR/CCPA and prevent the exposure of Sensitive Personal Information (SPI)?
- Monitoring: What alerts are in place to detect a drop in model performance before it affects the business?
By treating ML as a system engineering challenge rather than a mathematical puzzle, candidates and practitioners alike can build AI applications that are not only intelligent but also resilient, ethical, and commercially successful.








