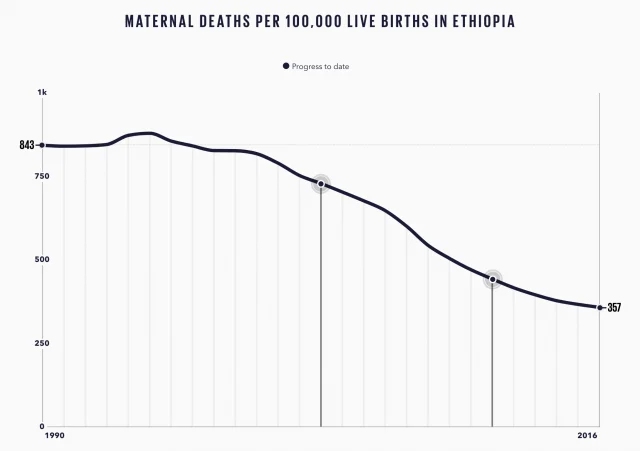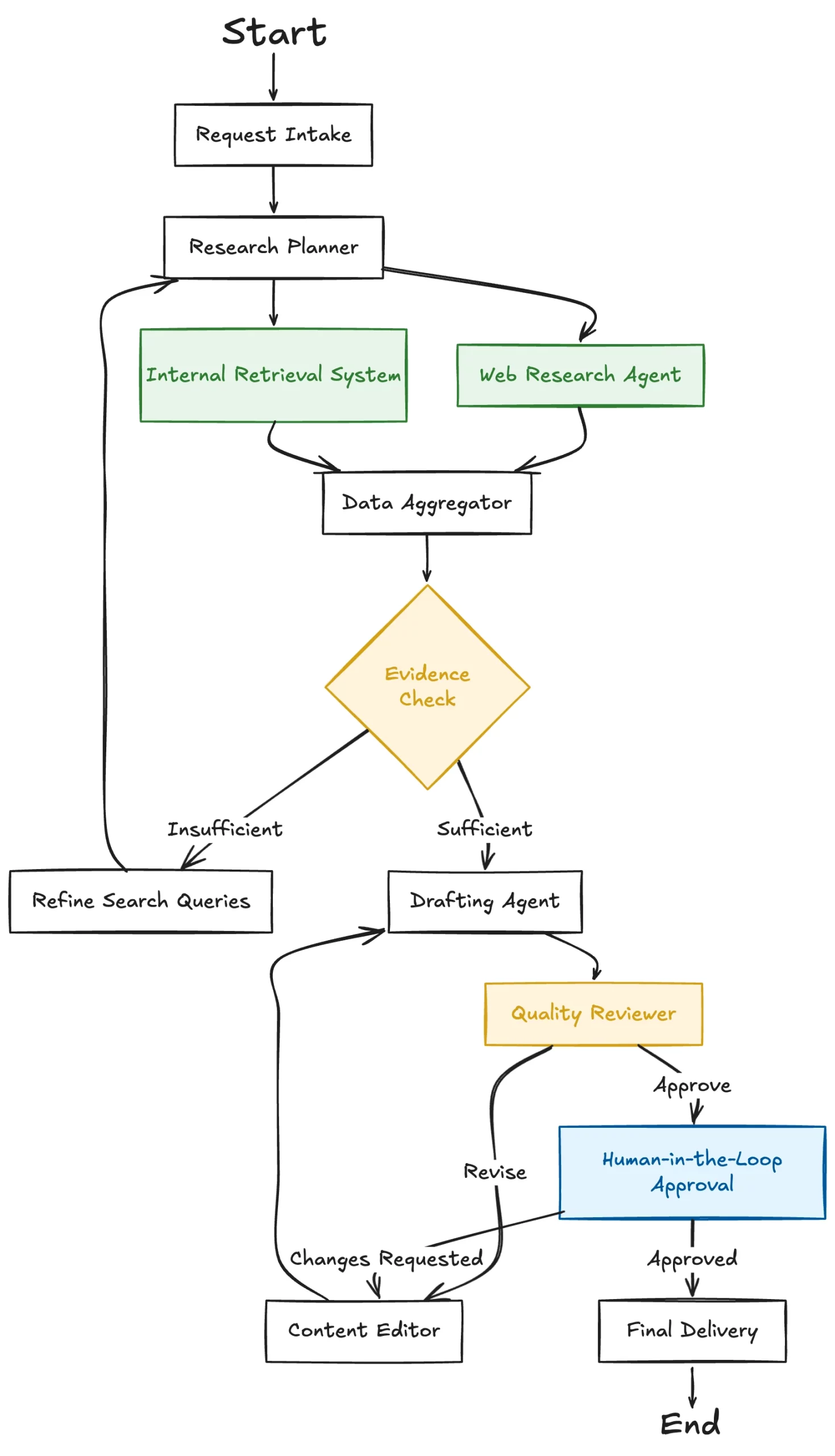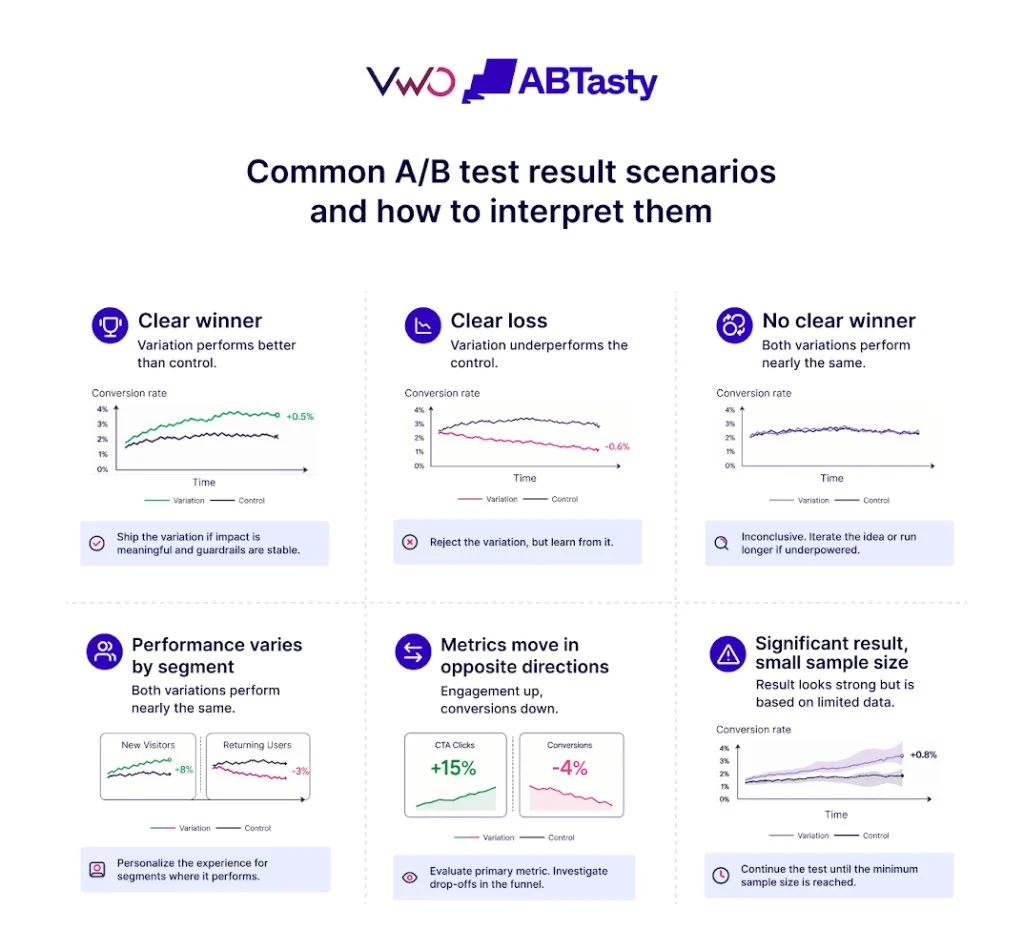
The paradigm of machine learning development is undergoing a fundamental shift as Large Language Models (LLMs) redefine the traditional processes of feature engineering. For decades, the efficacy of machine learning models was dictated by the "garbage in, garbage out" principle, where the quality of human-curated features determined the success of the algorithm. Historically, this process was manual, labor-intensive, and heavily reliant on domain experts to identify relevant signals within data. However, the emergence of transformer-based architectures has introduced a new era of semantic feature engineering, allowing machines to interpret context, sentiment, and intent from unstructured data with unprecedented precision.
The Evolution of Feature Engineering: From Manual Rules to Semantic Understanding
The history of feature engineering is a timeline of increasing abstraction. In the early days of predictive modeling, engineers relied on simple mathematical transformations, such as normalization and scaling, or categorical encoding methods like one-hot encoding. While these methods were effective for structured tabular data, they struggled with the nuance of human language.
By the 2010s, techniques such as Term Frequency-Inverse Document Frequency (TF-IDF) and Word2Vec began to bridge the gap by providing statistical representations of text. However, these methods remained "context-blind," treating words as isolated entities or fixed vectors. The introduction of the Transformer architecture in 2017 by Google researchers marked a turning point. Unlike its predecessors, the Transformer allowed for bidirectional context, meaning the representation of a word would change based on the words surrounding it.
Today, LLM-based feature engineering leverages these pretrained foundations to extract high-dimensional semantic signals. Instead of simply counting word occurrences, engineers now use models like GPT-4, Llama 3, or Mistral to "understand" the data. This shift represents a move from syntactic features—based on the structure of data—to semantic features, which are based on the meaning of the data.
Core Mechanics: Embeddings and Information Extraction
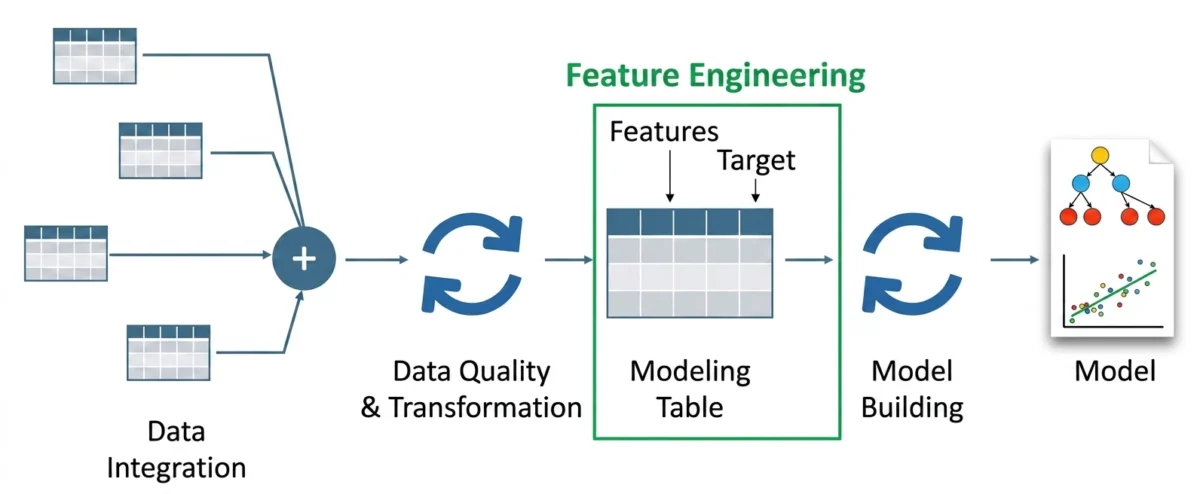
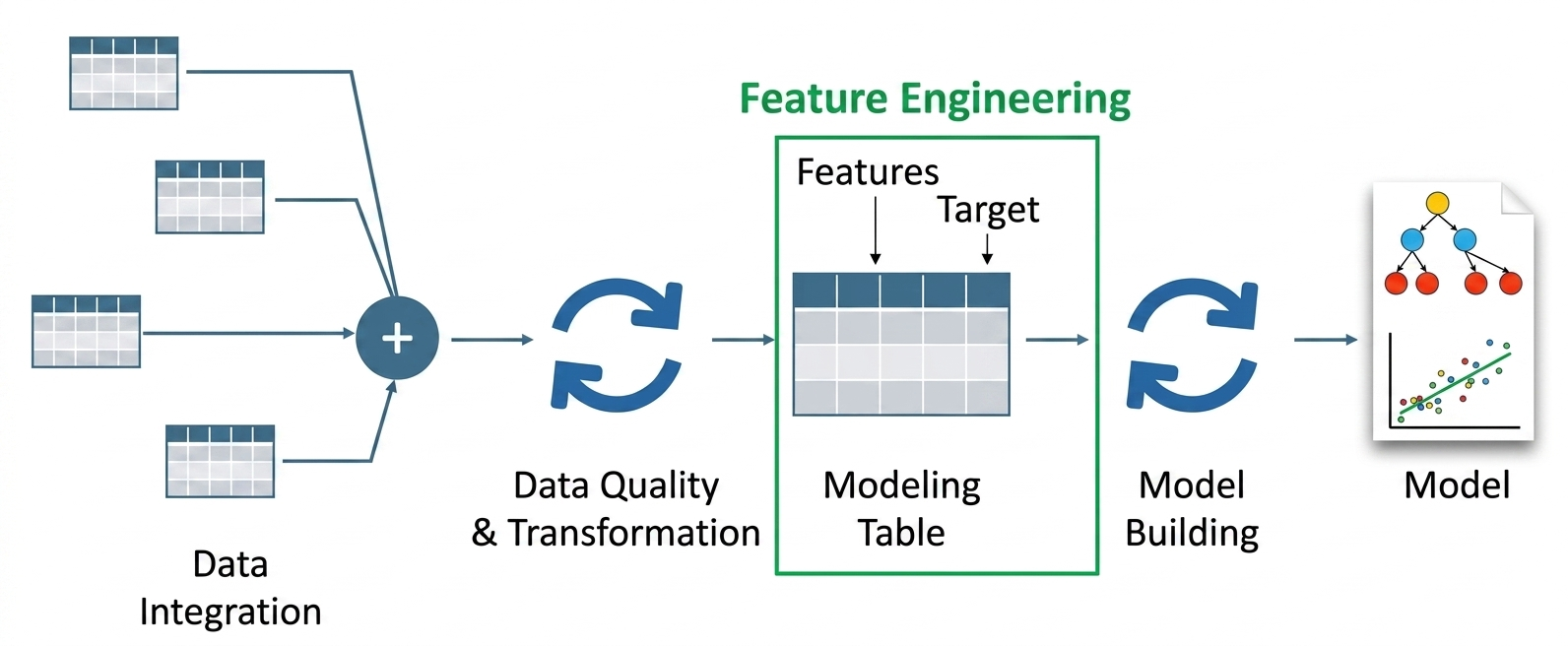
At the heart of LLM-driven feature engineering are two primary techniques: dense vector embeddings and structured information extraction. These methods allow data scientists to transform raw, noisy text into refined inputs that standard machine learning models, such as Random Forests or Gradient Boosting Machines, can ingest.
Dense Semantic Embeddings
Traditional NLP features like TF-IDF produce sparse matrices where most values are zero, leading to the "curse of dimensionality." In contrast, LLMs generate dense embeddings—vectors of fixed size (e.g., 384, 768, or 1536 dimensions) where every value is a real number representing a facet of meaning.

Using models such as all-MiniLM-L6-v2, developers can map entire sentences into a shared vector space. In this space, the distance between vectors represents semantic similarity. For instance, the sentences "The battery life is exceptional" and "The charge lasts a long time" would be positioned closely together, despite sharing very few identical words. This capability allows downstream models to recognize patterns across varied linguistic expressions, significantly boosting the robustness of sentiment classifiers and recommendation engines.
Structured Attribute Extraction
Beyond embeddings, LLMs serve as sophisticated "reasoning engines" capable of performing Zero-Shot or Few-Shot extraction. By prompting an LLM to identify specific attributes within a text—such as urgency, product defects, or user intent—engineers can convert qualitative reviews into quantitative features.
For example, an LLM can process a customer service log and output a structured JSON object containing features like sentiment_score, is_refund_request, and technical_complexity. These extracted labels then serve as high-quality categorical or numerical inputs for predictive models, effectively automating the role that domain experts used to play in labeling data.
Comparative Data: Traditional vs. LLM-Enhanced Pipelines
Recent industry benchmarks suggest that integrating LLM-derived features can lead to a 15% to 30% increase in model accuracy for tasks involving unstructured text. In a comparative analysis of a sentiment analysis task, a traditional TF-IDF approach yielded a feature matrix of size (N x 6) for a small sample, capturing only the presence of specific keywords. Conversely, an LLM-based embedding approach generated a (N x 384) matrix, capturing the emotional nuance and contextual relationships between words like "slow" and "overheating."
Furthermore, the "agentic" approach to feature engineering—where an LLM is used to autonomously generate new feature ideas based on data descriptions—has shown promise in reducing the development cycle. What previously took weeks of brainstorming and A/B testing can now be prototyped in hours through automated prompt engineering.
Hybrid Feature Spaces and Multi-Modal Pipelines
The most sophisticated modern ML systems do not rely solely on LLMs; instead, they utilize hybrid feature spaces. These pipelines combine traditional tabular data (price, timestamps, demographics) with semantic features (text embeddings, image vectors).
In a retail price prediction model, for example, a hybrid pipeline might combine:
- Tabular Data: Original price, discount percentage, and stock levels.
- Semantic Data: Embeddings derived from the product description.
- Extracted Data: LLM-identified "style tags" or "trend scores" from user reviews.
By concatenating these diverse feature sets into a single vector, the model gains a holistic view of the product, understanding both its market position (tabular) and its consumer perception (semantic).
Industry Reactions and Real-World Applications
The adoption of LLM-based feature engineering has sparked significant interest across various sectors:
- Financial Services: Banks are using LLMs to extract sentiment and risk signals from news articles and earnings call transcripts to augment algorithmic trading models. Analysts note that these features provide a "leading indicator" that traditional financial ratios often miss.
- Healthcare: Medical researchers are leveraging LLMs to feature-engineer patient notes, transforming narrative clinical observations into structured data for disease progression models.
- E-commerce: Platforms like Amazon and eBay use semantic features to improve search relevance, ensuring that a search for "waterproof footwear" returns results for "rain boots" even if the specific keyword is missing.
Industry experts from organizations like OpenAI and Google DeepMind have suggested that the future of AI lies in "Foundation Feature Engineering," where a single massive model provides the "intelligence layer" for thousands of smaller, specialized models.
Challenges: Cost, Latency, and Ethics
Despite the technical advantages, the integration of LLMs into feature engineering pipelines is not without hurdles. The primary concerns cited by data engineering teams include:
- Computational Cost: Generating embeddings for millions of rows of data can be expensive, particularly when using proprietary APIs.
- Inference Latency: LLMs are computationally heavy. Real-time feature extraction—such as analyzing a user’s intent during a live chat—requires significant infrastructure optimization or the use of smaller, distilled models.
- Bias and Hallucination: LLMs can inherit biases present in their training data. If an LLM is used to extract "creditworthiness" features from a loan application narrative, there is a risk of introducing non-objective criteria that could lead to discriminatory outcomes.
- Interpretability: Unlike a "number of clicks" feature, a 768-dimensional embedding is a "black box." Explaining why a model made a specific prediction becomes more difficult when the input features themselves are abstract vectors.
Chronology of Progress in NLP Feature Engineering
- 1950s-1990s: Dominance of Rule-Based Systems and basic frequency counts (Bag-of-Words).
- 2003: Introduction of Neural Probabilistic Language Models, laying the groundwork for word embeddings.
- 2013: Release of Word2Vec, popularizing dense but context-static vectors.
- 2018: BERT (Bidirectional Encoder Representations from Transformers) introduces context-aware embeddings.
- 2020-2022: GPT-3 and the rise of "Prompt Engineering" as a tool for data transformation.
- 2023-Present: Widespread adoption of "Agentic Workflows" where LLMs autonomously manage the feature engineering lifecycle.
Conclusion and Future Outlook
Feature engineering with LLMs represents a fundamental shift in how we build intelligent systems. By moving beyond simple data transformations and into the realm of semantic comprehension, developers can unlock the hidden value within unstructured data. While challenges regarding cost and interpretability remain, the trajectory of the industry is clear: the most successful machine learning models of the next decade will be those that can "read" and "understand" their inputs as well as they can "calculate" them.
As small language models (SLMs) become more capable, we expect to see a democratization of these techniques, allowing semantic feature engineering to run locally on edge devices. This evolution will further close the gap between raw data and actionable intelligence, cementing the LLM’s role not just as a chatbot, but as the foundational engine of modern data science.