The global retail sector is currently undergoing a paradigm shift as artificial intelligence moves from centralized cloud servers to the "edge"—store-level devices, handheld scanners, and Internet of Things (IoT) sensors. This transition is driven by the need for real-time responsiveness in demand forecasting, inventory management, and shelf optimization. However, deploying sophisticated deep learning models, such as Long Short-Term Memory (LSTM) networks, on edge hardware presents significant engineering challenges. These devices often operate under strict constraints, including limited volatile memory, restricted battery life, and the requirement for low-latency processing without constant cloud connectivity. For small to medium-sized retail enterprises, the high cost of cloud APIs and specialized hardware makes model compression not just a technical preference, but a financial necessity.
The Landscape of Retail Edge AI
In modern retail environments, the ability to predict inventory needs at the "shelf level" can mean the difference between a satisfied customer and a lost sale. Traditional cloud-based forecasting models often suffer from network latency and high operational costs when scaled across thousands of stock-keeping units (SKUs). By moving these models to edge devices, such as smart cameras or mobile inventory apps, retailers can achieve instantaneous insights. However, a standard LSTM model, while effective for time-series forecasting, may be too bulky for a device with only a few megabytes of available RAM.
Industry data suggests that the cost of running a 64KB model in a cloud environment, when scaled across a massive product catalog with millions of daily predictions, is significantly higher than maintaining a compressed 4KB model. Furthermore, the energy efficiency of smaller models extends the battery life of portable retail devices, reducing the total cost of ownership for hardware deployments.
Experimental Methodology and Benchmarking Framework
To evaluate the efficacy of various compression strategies, researchers utilized the Kaggle Store Item Demand Forecasting dataset. This dataset provides a robust foundation for simulation, containing five years of daily sales data across 10 stores and 50 unique items. The data exhibits classic retail patterns, including weekly seasonality, long-term trends, and stochastic noise.
The experimental setup focused on a sample of five stores and 10 items, creating 50 distinct time series. This resulted in approximately 72,000 training samples. The primary task for the AI was a single-step daily sales prediction based on the previous 14 days of sales history—a standard window for short-term inventory restocking. To ensure statistical reliability, every experiment was conducted three times, with results averaged to account for variance in model initialization and training convergence. The primary metric for success was the Mean Absolute Percentage Error (MAPE), which measures the accuracy of the forecast relative to actual sales volumes.
The Baseline: Establishing the Reference Point
Before applying compression, a baseline LSTM model was established. This model utilized 64 hidden units and was trained using a standard 32-bit floating-point (FP32) precision.
Baseline Specifications:
- Model Type: LSTM-64
- Storage Size: 66.25 KB
- MAPE (Accuracy): 15.92%
- MAPE Standard Deviation: ±0.10%
This baseline represents the "uncompressed" state. While 66.25 KB may seem small by modern computing standards, in the context of microcontrollers and embedded IoT sensors, it remains a significant footprint, especially when multiple models must reside in memory simultaneously.
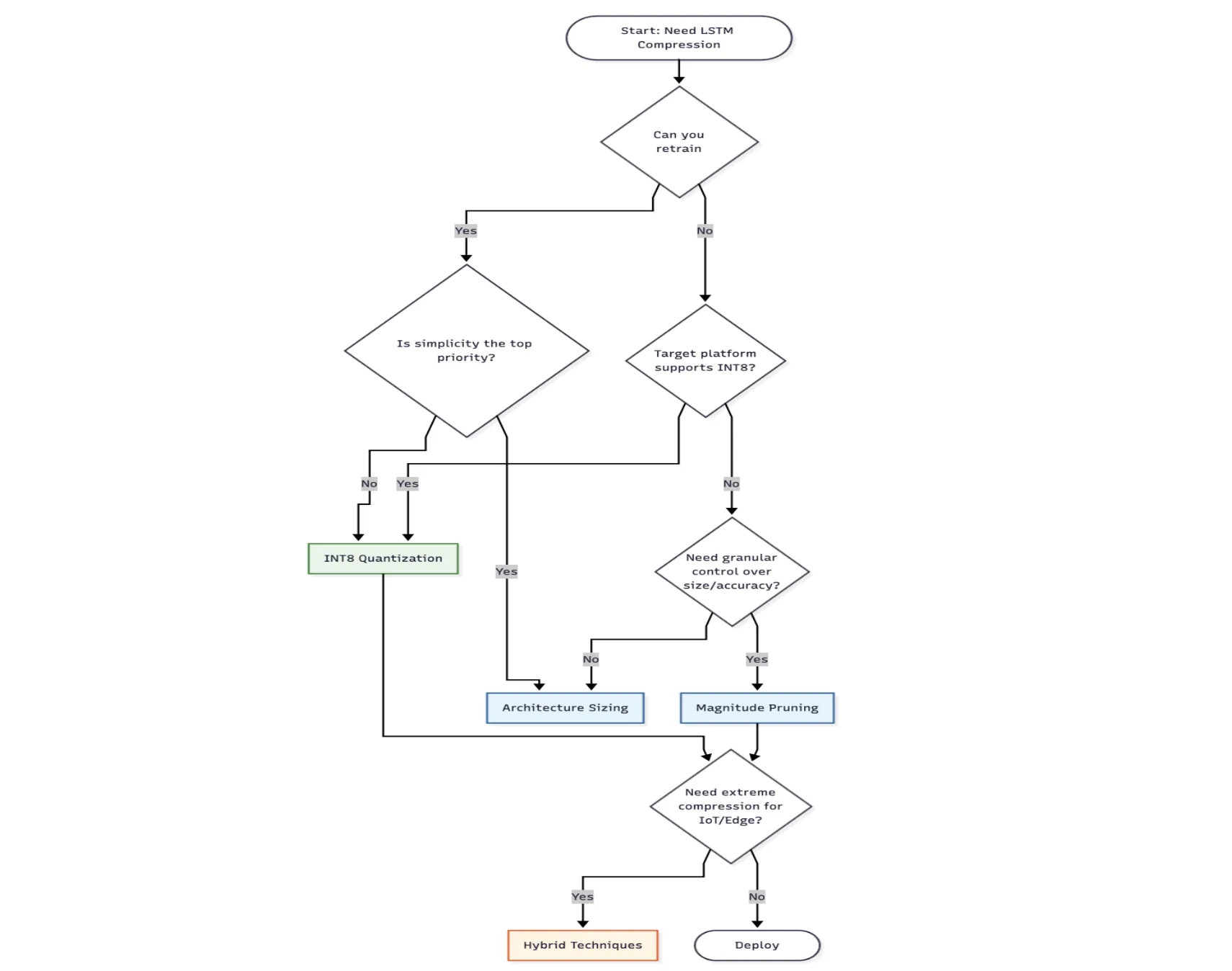
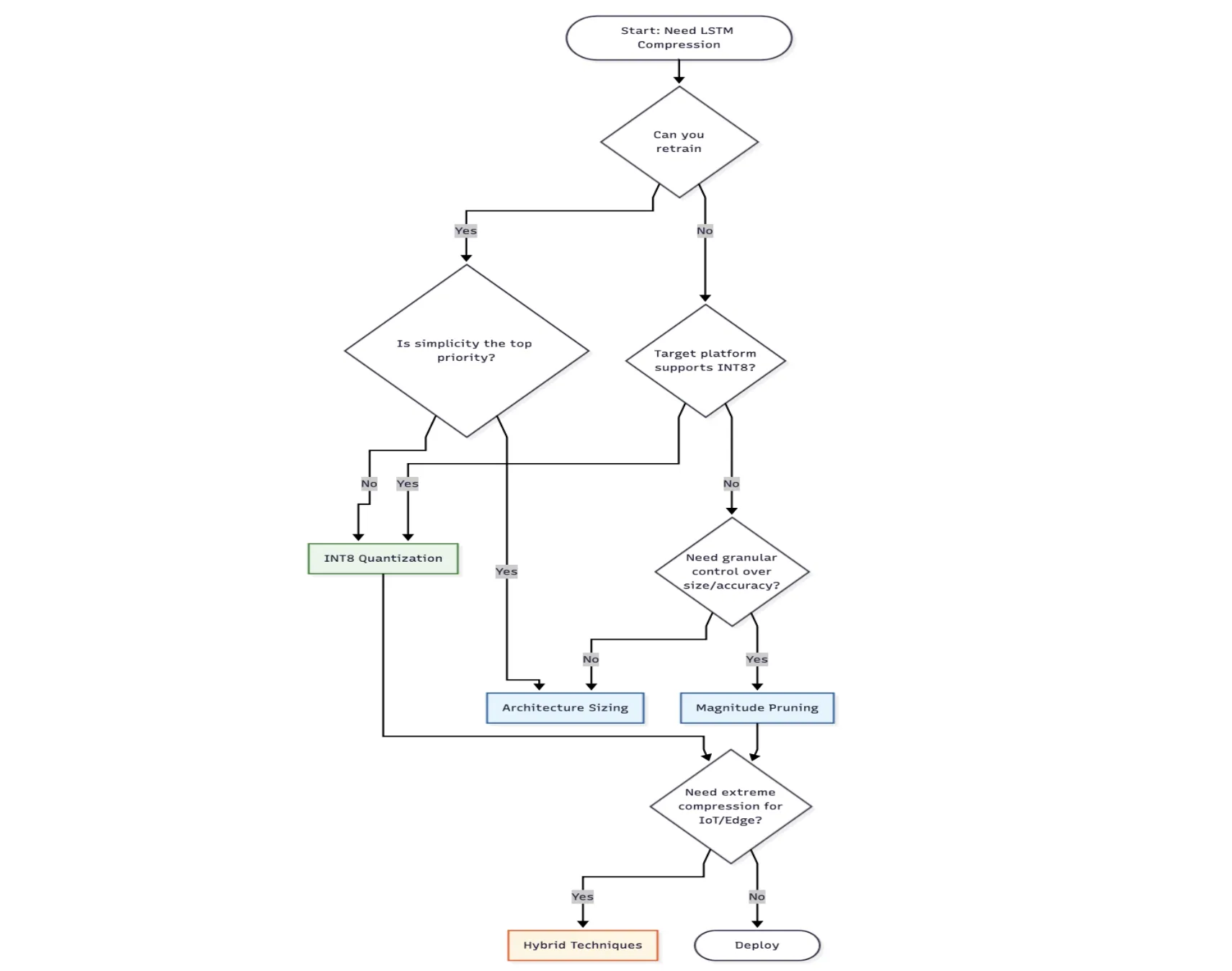
Strategy 1: Architecture Sizing (The "Top-Down" Approach)
The most straightforward method of model compression is architecture sizing, which involves reducing the number of hidden units within the neural network layers. This approach assumes that the baseline model may be "over-parameterized" for the specific task of store-level forecasting.

By training smaller versions of the LSTM from scratch, researchers compared the performance of 32-unit and 16-unit models against the 64-unit baseline.
Results of Architecture Sizing:
- LSTM-32: Reduced size to 17.13 KB (3.9x compression) with a MAPE of 16.22%.
- LSTM-16: Reduced size to 4.57 KB (14.5x compression) with a MAPE of 16.74%.
The analysis reveals that the LSTM-16 model achieves a massive 14.5x reduction in size while only sacrificing 0.82% in accuracy. In many retail scenarios, such as predicting the number of milk cartons to stock, a sub-1% increase in error is negligible compared to the benefits of running the model on a low-cost, low-power device.
Strategy 2: Magnitude Pruning (The "Surgical" Approach)
Magnitude pruning involves identifying and removing neural network connections (weights) that contribute the least to the final output. The underlying theory is that many weights in a trained model are near zero and do not significantly influence the prediction. By setting these weights to zero and fine-tuning the remaining connections, the model becomes "sparse."
A critical finding during this phase was that LSTMs require a nuanced pruning strategy. Unlike standard feed-forward networks, LSTMs have recurrent weights that are highly interdependent. To maintain accuracy, researchers applied thresholds at every individual layer rather than using a global threshold. Furthermore, bias weights were skipped to preserve the model’s basic functionality, and a lower learning rate was employed during the fine-tuning phase.
Results of Magnitude Pruning:
- 30% Sparsity: 11.99 KB size, 16.04% MAPE (0.12% accuracy loss).
- 50% Sparsity: 8.56 KB size, 16.20% MAPE (0.28% accuracy loss).
- 70% Sparsity: 5.14 KB size, 16.84% MAPE (0.92% accuracy loss).
Pruning at 50% sparsity emerged as a "sweet spot," offering a 7.7x compression ratio with virtually no perceptible impact on forecasting reliability.
Strategy 3: INT8 Quantization (The "Precision" Approach)
Quantization is the process of converting the model’s weights from 32-bit floating-point numbers to 8-bit integers. This theoretically reduces the model size by a factor of four. However, because the range of values is restricted to 256 possible integers (0–255), a dequantization scale and "zero-point" must be calculated to map the integers back to the original numerical range during inference.
This technique is highly favored for edge deployment because many modern mobile processors and specialized AI accelerators are optimized for integer arithmetic, which is faster and consumes less power than floating-point math.
Results of INT8 Quantization:
- Model Size: 4.28 KB
- Compression Ratio: 15.5x
- MAPE: 16.21% (0.29% accuracy loss)
Quantization provided the best overall trade-off, delivering the highest compression ratio (15.5x) while keeping the accuracy loss exceptionally low at 0.29%. This makes it the gold standard for production-ready retail AI.
Comparative Analysis and Industry Implications
When placed side-by-side, the three techniques offer distinct advantages depending on the deployment environment.
| Technique | Compression Ratio | Accuracy Impact (MAPE) |
|---|---|---|
| LSTM-32 (Sizing) | 3.9x | +0.30% |
| LSTM-16 (Sizing) | 14.5x | +0.82% |
| Pruned-50% | 7.7x | +0.28% |
| Pruned-70% | 12.9x | +0.92% |
| INT8 Quantization | 15.5x | +0.29% |
The data indicates that for retailers seeking the smallest possible footprint with high accuracy, INT8 Quantization is the superior choice. However, for organizations with limited machine learning expertise, Architecture Sizing (reducing units) provides a low-complexity alternative that still yields significant results. Pruning remains a niche but powerful tool for developers who need fine-grained control over specific layers of a model.
Expert Perspectives on Retail Deployment
Technical experts in the retail sector emphasize that model compression is only one component of a successful edge strategy. Senior engineers, including those specializing in supply chain optimization, note that "data drift" is a significant concern. Because retail patterns change seasonally or due to external economic shocks, even a perfectly compressed model must be monitored for performance degradation over time.
Furthermore, the choice of compression often dictates the hardware choice. For instance, if a retailer chooses INT8 Quantization, they must ensure their edge devices support integer-based inference runtimes like TensorFlow Lite or ONNX Runtime. Conversely, if the hardware only supports standard Python environments, pruning or sizing might be more appropriate.
Chronology of Implementation
For a retail chain looking to adopt these technologies, the implementation timeline typically follows a structured path:
- Month 1-2: Data collection and baseline model development using historical sales data.
- Month 3: Evaluation of compression techniques in a simulated environment to determine the acceptable accuracy-to-size trade-off.
- Month 4: Pilot testing on a limited number of edge devices (e.g., in five flagship stores).
- Month 5-6: Fine-tuning of models based on real-world edge performance and eventual chain-wide rollout.
Conclusion: The Future of Small-Scale AI
The move toward compressed AI models represents a democratization of technology. By reducing the size of an LSTM model from 66KB to 4KB, the requirement for expensive, high-end hardware is eliminated. This allows small-scale retailers to compete with industry giants by utilizing smart inventory systems that run on basic tablets or inexpensive sensors.
As AI continues to mature, the focus is shifting from "bigger is better" to "smaller is smarter." In the competitive world of retail, where margins are thin and efficiency is paramount, the ability to run accurate, fast, and tiny models at the edge is no longer a luxury—it is a foundational requirement for the digital storefront of the future. The success of INT8 quantization and aggressive pruning in these experiments proves that with the right engineering approach, AI can be both powerful and incredibly portable.