In the modern digital economy, the ability to iterate rapidly has transitioned from a competitive advantage to a fundamental requirement for survival. Most corporate optimization journeys follow a predictable trajectory: a small, dedicated team initiates a handful of A/B tests, achieves a series of high-visibility "quick wins," and subsequently garners the attention of senior leadership. This initial success often acts as a catalyst, transforming experimentation from a niche technical initiative into a strategic lever for organizational growth. However, as organizations attempt to transition from running five tests a month to fifty, they frequently encounter a "scaling ceiling" where the informal processes that served them in the early stages begin to buckle under the weight of increased complexity.
The shift from a localized testing effort to an enterprise-wide experimentation culture is rarely a linear progression. It involves a fundamental re-engineering of how data is collected, how hypotheses are prioritized, and how insights are disseminated across disparate departments. When the infrastructure for governance fails to keep pace with the demand for test velocity, the integrity of the entire program is placed at risk. Industry analysts note that without a robust framework, the very data intended to drive decision-making can become a source of internal confusion and strategic misalignment.
The Chronology of Experimentation Maturity
To understand the pitfalls of scaling, one must first examine the typical lifecycle of a corporate experimentation program. This evolution generally occurs in four distinct phases, each presenting its own set of operational hurdles.
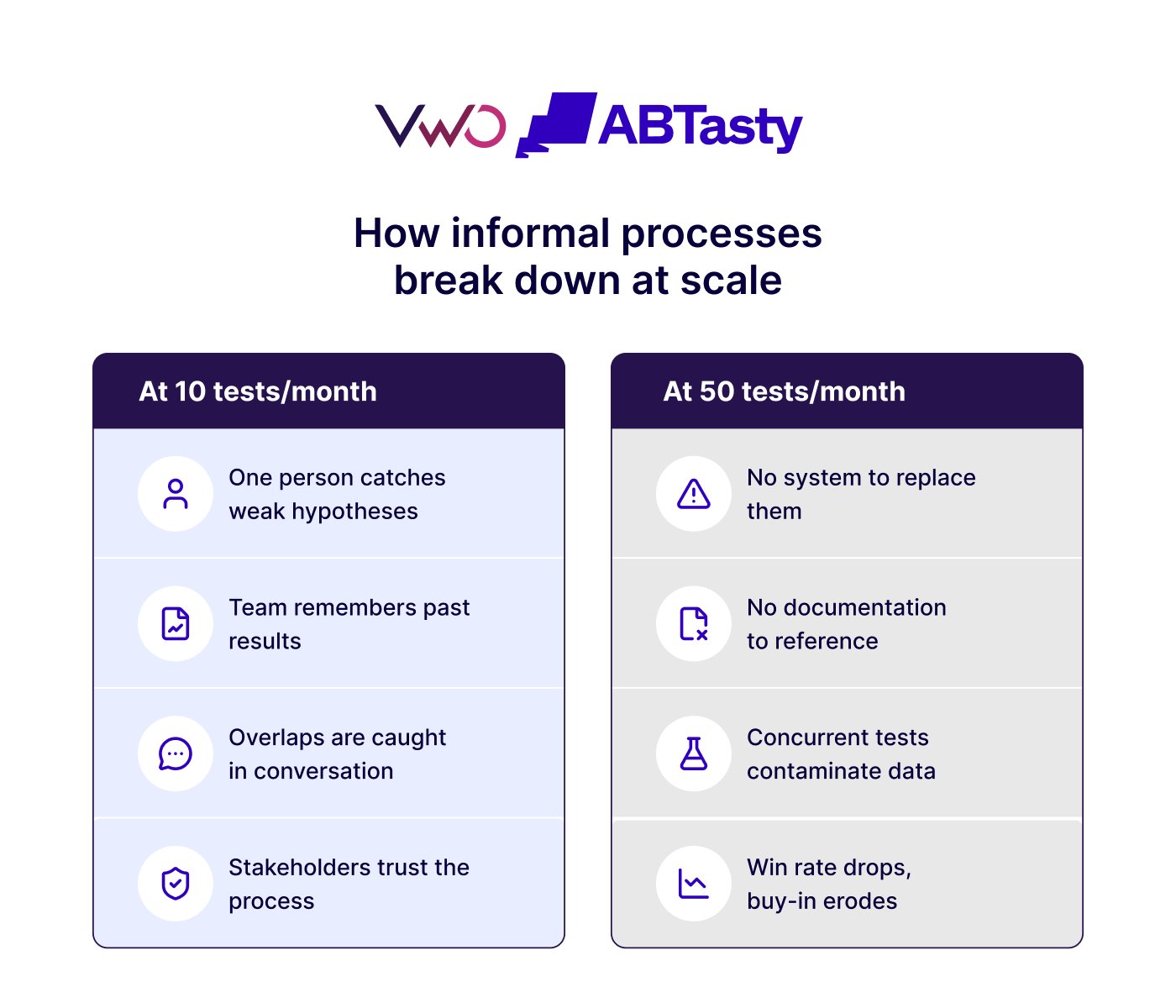
The first phase, often termed the "Proof of Concept" stage, is characterized by low volume and high manual oversight. Tests are typically managed through shared spreadsheets and ad-hoc communication. Because the volume is low, the risk of test overlap is negligible, and the primary goal is simply to prove that the methodology works.

The second phase is the "Expansion" stage. Following initial successes, demand for testing spreads to other departments—marketing, product, and customer success all seek to validate their own roadmaps. It is during this phase that the first cracks in the foundation usually appear. Documentation becomes inconsistent, and different teams begin to adopt conflicting key performance indicators (KPIs).
The third phase is the "Scaling Crisis." At this juncture, the organization is running a high volume of concurrent experiments. Without centralized governance, teams unknowingly contaminate each other’s data. The pressure to report "wins" to leadership leads to statistical shortcuts, such as premature test termination. This stage is a critical inflection point; the program will either professionalize its operations or collapse under the weight of unreliable data.
The final phase is "Institutionalized Experimentation." Successful organizations at this level have integrated testing into the very fabric of their product development lifecycle. Governance is automated through sophisticated tooling, and a centralized repository ensures that every insight—regardless of which team generated it—is accessible to the entire enterprise.
Identifying the Structural Pitfalls of High-Velocity Testing
As organizations push for higher test velocity, five specific pitfalls frequently emerge, each capable of derailing an otherwise healthy program.
1. The Statistical Danger of Premature Termination
In an effort to meet aggressive testing schedules, teams often succumb to the "peeking problem." When a test shows a positive trend within the first few days, there is a strong temptation to declare a winner and move on to the next experiment. However, conversion rates are notoriously volatile in the early stages of a test.

Statisticians warn that "peeking" at data and stopping tests early significantly inflates the rate of false positives. A result that appears significant at day five may regress to the mean by day fourteen. When these false winners are implemented, they fail to deliver the expected downstream revenue or engagement lifts. Over time, a backlog of these "phantom wins" erodes the organization’s trust in the experimentation program, leading leadership to question the validity of the data altogether.
2. The High Cost of Knowledge Silos
One of the most significant wastes of corporate resources is the "re-testing" of hypotheses that have already been validated or debunked by another team. In large organizations, the marketing team in North America might spend three weeks testing a checkout flow modification that the European product team already proved ineffective six months prior.
Without a shared test repository, insights remain trapped within the teams that generated them. A scaled program requires more than just a tool for running tests; it requires a library for institutional memory. When learnings are not compounded, the program stagnates, repeating the same mistakes rather than building toward more sophisticated, high-impact hypotheses.
3. Metric Fragmentation and Inconsistent Standards
As experimentation democratizes across an organization, different teams often bring different definitions of "success" to the table. A marketing team might prioritize click-through rates (CTR) and operate at an 80% confidence interval to move quickly. Simultaneously, a product team might focus on long-term retention and refuse to ship any change that hasn’t reached a 95% significance threshold.
When these teams meet in a boardroom to discuss the overall health of the customer journey, their data is often incomparable. Inconsistent measurement standards create a "Tower of Babel" effect where the organization lacks a single source of truth. Establishing a unified experimentation charter that defines significance thresholds, minimum sample sizes, and primary vs. secondary metrics is essential for maintaining data integrity at scale.

4. The Interaction Effect and Data Contamination
At low volumes, the likelihood of a single user being enrolled in two different experiments is low. At scale, it becomes an inevitability. If a user is simultaneously part of a pricing experiment on the landing page and a navigation experiment on the product page, it becomes nearly impossible to isolate which variable influenced their behavior.
These interaction effects create "noise" in the data that can lead to incorrect conclusions. Advanced programs solve this through "mutual exclusivity" configurations, ensuring that users are partitioned into distinct groups that do not overlap across conflicting tests. Without this technical safeguard, the data produced by high-volume testing is often too contaminated to be actionable.
5. The Infrastructure Gap
Many organizations attempt to run enterprise-level programs using entry-level tools. While a basic script might suffice for a single-page A/B test, it lacks the sophisticated governance features required for multi-team coordination. Enterprise-grade experimentation requires role-based access controls, workflow approval processes, and centralized visibility. When the scope of the program outgrows the capabilities of the tooling, the operational overhead of managing the program manually becomes a bottleneck that stifles growth.
Expert Perspectives on the Cultural Shift
The transition to scaled testing is as much a cultural challenge as a technical one. Rafael Damasceno, a prominent figure in the conversion rate optimization (CRO) space, argues that the limitations of many programs stem from a lack of executive mandates. According to Damasceno, if leadership does not demand an experimentation mindset across all departments, the CRO team remains siloed, limited to making incremental gains on isolated web pages rather than influencing core business drivers like pricing models or product features.
Similarly, Sarah Fruy, an expert in personalization and experimentation, emphasizes the shift in operational reality. In recent industry discussions, Fruy noted that the transition from a "scrappy" single-team setup to a cross-functional program introduces significant operational overhead. Without proper infrastructure, the time spent on coordination and governance can quickly exceed the time spent on actual testing, leading to a paradox where more resources result in fewer insights.

Strategic Recommendations for Sustainable Scaling
To avoid these pitfalls, organizations must view experimentation as a product in itself, requiring its own roadmap and infrastructure.
First, the "Pre-Registration" of test parameters is vital. Before any experiment goes live, the team must commit to a minimum sample size and a specific duration. By treating these as immutable launch conditions, the temptation to "peek" and stop tests early is removed.
Second, the implementation of a centralized "Experimentation Hub" is non-negotiable. This platform should serve as the definitive record of every hypothesis tested, the data gathered, and the business impact realized. This visibility allows for the cross-pollination of ideas and prevents the duplication of effort.
Third, organizations must invest in "Guardrail Metrics." While a team might be testing for a lift in sign-ups, they must also monitor for negative impacts on long-term retention or customer support volume. A scaled program recognizes that a "win" in one area is a failure if it causes a "loss" elsewhere in the ecosystem.
The Broader Impact of Scaled Experimentation
The implications of successfully scaling an experimentation program extend far beyond website conversion rates. Organizations that master this discipline develop a "high-resolution" understanding of their customers. This data-driven culture reduces the risk associated with major product launches and allows for more agile responses to market shifts.
Furthermore, in an era where artificial intelligence and machine learning are increasingly integrated into the customer experience, experimentation serves as the essential "feedback loop." It provides the ground-truth data necessary to train algorithms and validate AI-driven interventions.
In conclusion, scaling A/B testing is not merely about increasing the number of experiments; it is about building a robust, governed, and transparent ecosystem that turns every customer interaction into a learning opportunity. The organizations that thrive in the coming decade will be those that move past the "trial and error" phase and treat experimentation as a core, scalable competency. By addressing the structural pitfalls of premature termination, knowledge silos, and fragmented standards, enterprises can ensure that their growth is built on a foundation of statistical rigor rather than optimistic guesswork.