The increasing reliance on large-scale data processing has placed Apache Spark at the center of the modern enterprise data stack, yet the efficiency of these systems remains a primary concern for data architects and engineers globally. As datasets expand into the petabyte range, the cost and latency associated with poorly optimized Spark jobs have become significant liabilities for organizations operating in the cloud. In response to these challenges, a set of 12 standardized optimization techniques has emerged as the industry benchmark for enhancing PySpark performance, reducing infrastructure overhead, and ensuring the scalability of data pipelines.

The Foundation of Spark Execution and Performance Architecture
To implement effective optimization, one must first understand the underlying mechanics of the Spark engine. Apache Spark operates as a distributed computing framework that utilizes a master-slave architecture. The “Driver” program serves as the orchestrator, responsible for converting user code into a logical directed acyclic graph (DAG) and scheduling tasks across “Executors.” These executors are worker nodes that reside on different machines in a cluster, performing the actual data processing and storage tasks in memory.
A critical component of Spark’s efficiency is “Lazy Evaluation.” Unlike traditional procedural programming, Spark does not execute transformations—such as filter() or select()—immediately. Instead, it records these operations in a lineage. Execution only commences when an “Action,” such as collect(), count(), or save(), is triggered. This delay allows the Catalyst Optimizer to analyze the entire execution plan and rearrange operations for maximum efficiency, such as pushing filters closer to the data source to minimize the volume of data loaded into memory.
Optimizing Data Storage and Retrieval
The first line of defense against performance degradation lies in how data is stored and accessed. Industry data suggests that the choice of file format can impact read speeds by as much as 10 times.
Transitioning to Columnar Formats
While CSV and JSON are human-readable and widely used for small-scale data exchange, they are row-based and inefficient for analytical workloads. In a row-based format, Spark must read every column in a row even if the query only requires two. Conversely, columnar formats like Apache Parquet and ORC (Optimized Row Columnar) allow Spark to read only the specific columns needed. Furthermore, Parquet supports “Predicate Pushdown,” which enables the system to filter data at the storage level rather than loading the entire dataset into memory and filtering it afterward.
Strategic Column Selection and Filtering
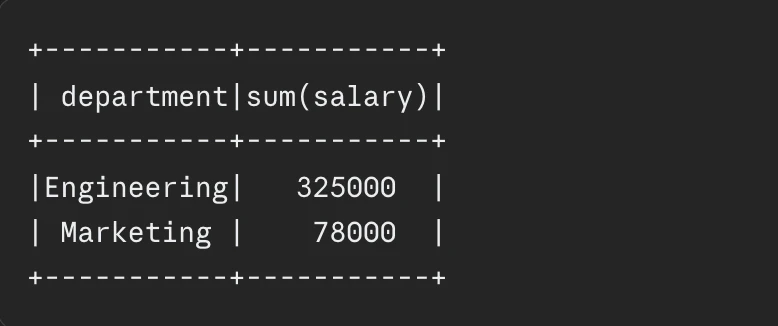
Data engineers frequently default to select("*") during development, a practice that proves disastrous in production environments with wide tables. By implementing “Column Pruning”—explicitly selecting only the necessary fields—engineers reduce the I/O burden and memory footprint of the job. Coupled with early filtering, where criteria are applied as soon as the data is read, this ensures that the subsequent stages of the pipeline process the smallest possible subset of data.
Managing the Shuffle and Partitioning Logic
In Spark, the “Shuffle” is the process of redistributing data across the cluster so that related data resides on the same executor. It is widely considered the most expensive operation in distributed computing due to its heavy reliance on disk I/O, network bandwidth, and CPU serialization.

Partitioning Strategies
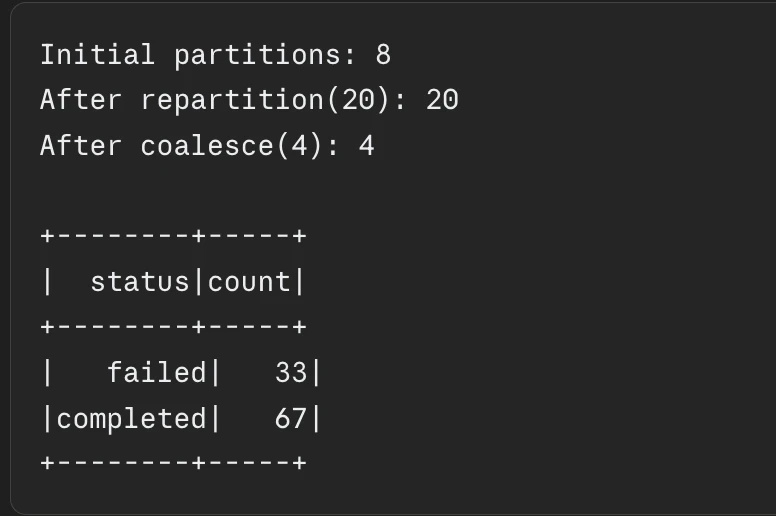
The number of partitions determines the level of parallelism in a Spark job. If there are too few partitions, executors remain idle while one node struggles with a massive data chunk. If there are too many, the overhead of managing thousands of tiny tasks can exceed the actual processing time. The industry standard recommendation is to maintain 2 to 4 partitions per CPU core.
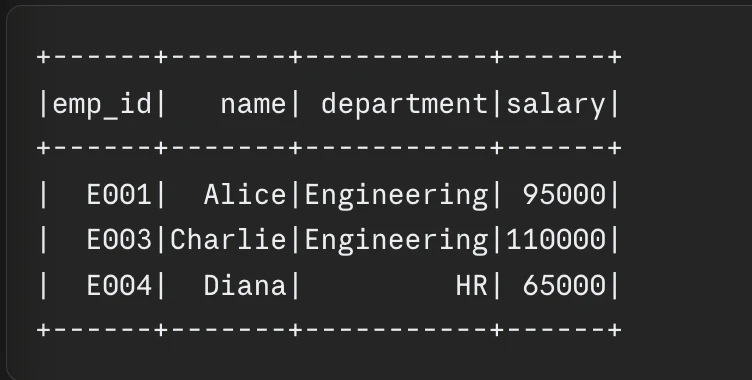
Engineers must choose between repartition() and coalesce() when adjusting partition counts. repartition() performs a full shuffle to increase or decrease the number of partitions, ensuring a uniform distribution. coalesce(), however, is an optimized version used only to reduce the number of partitions; it avoids a full shuffle by merging existing partitions, making it significantly faster for down-scaling data before writing to a final destination.
Bucketing for Repeated Joins
For datasets that are frequently joined on the same key, “Bucketing” offers a permanent optimization. By pre-sorting and organizing data into a fixed number of “buckets” on disk based on a join key, Spark can bypass the shuffle phase during future join operations. This technique is particularly effective in data warehousing scenarios where large fact tables are repeatedly joined with dimension tables.
Advanced Join Optimization and Adaptive Query Execution
Joins represent the most common cause of “Out of Memory” (OOM) errors and performance bottlenecks in PySpark.
Broadcast Joins
When joining a large table with a significantly smaller one (typically under 10MB by default, though configurable), Spark can utilize a “Broadcast Join.” The driver sends a full copy of the small table to every executor. This allows the join to occur locally on each node without any data movement from the large table across the network. For tables that fit in executor memory, this can reduce join times from hours to minutes.
Adaptive Query Execution (AQE)
Introduced in Spark 3.0, AQE represents a paradigm shift in optimization. Historically, Spark generated a static execution plan before the job started. AQE allows Spark to re-optimize the plan mid-execution based on the statistics of the data processed in earlier stages. It can dynamically coalesce shuffle partitions, switch join strategies (e.g., moving from a Sort-Merge join to a Broadcast join if the data size is smaller than expected), and handle data skew automatically.
Addressing Programming Pitfalls: UDFs and Caching
The interface between Python and the Spark JVM (Java Virtual Machine) can introduce significant overhead if not managed correctly.
Avoiding Python User Defined Functions (UDFs)
Python UDFs are often a bottleneck because Spark must serialize data from the JVM, send it to a Python process, execute the function, and then serialize it back to the JVM. This “context switching” is highly inefficient. Experts recommend using native Spark SQL functions (pyspark.sql.functions) whenever possible, as these are pre-compiled in the JVM and run at native speeds. If a custom logic is unavoidable, “Pandas UDFs” (Vectorized UDFs) utilize Apache Arrow to transfer data in batches, offering a middle ground in terms of performance.
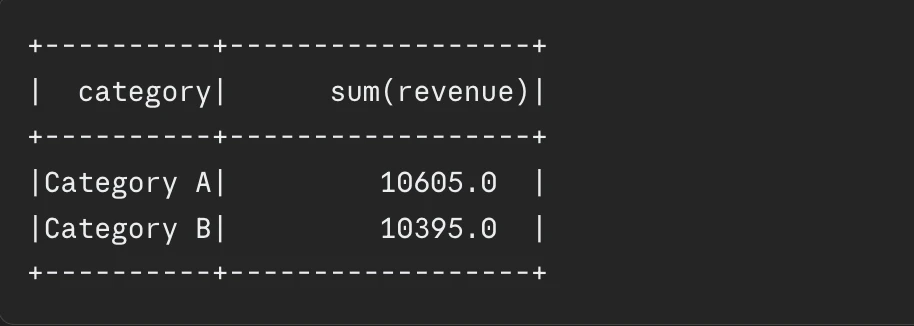
Strategic Caching and Persistence
Caching is a powerful tool for iterative algorithms or pipelines where the same DataFrame is accessed multiple times. By calling .cache() or .persist(), the results of a computation are stored in memory across the cluster. However, excessive caching can lead to memory pressure and “spilling” to disk, which slows down the system. A disciplined approach—unpersisting dataframes once they are no longer needed—is essential for maintaining cluster health.
Mitigating Data Skew
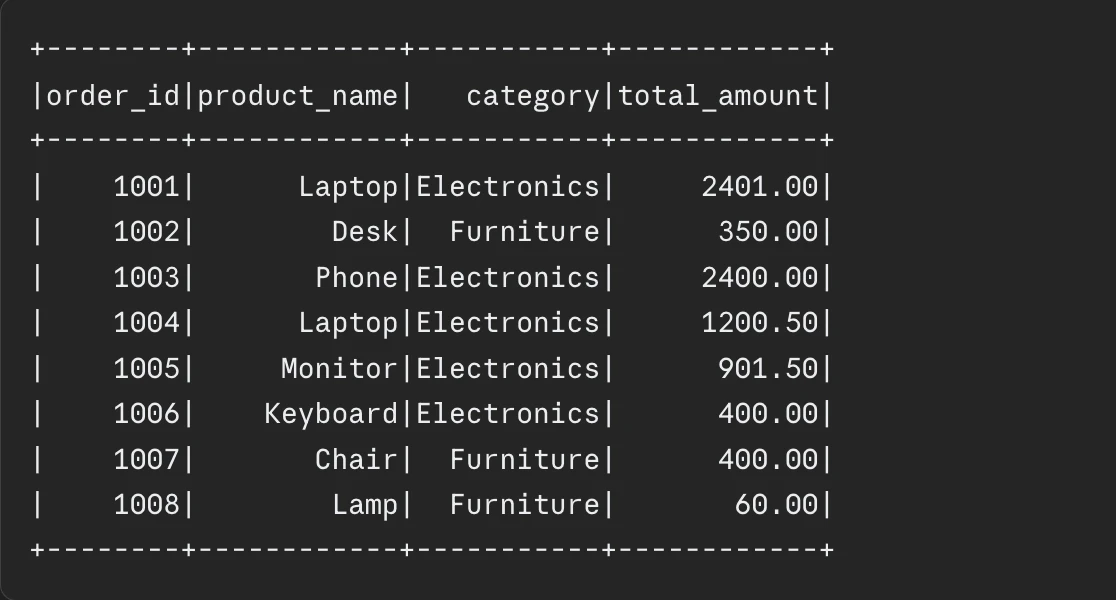
Data skew occurs when a few partitions hold the vast majority of the data, leading to a “straggler” effect where 99% of tasks finish quickly, but the job hangs on the last 1%. This often happens when joining on keys that are not uniformly distributed, such as a “null” value or a highly popular category.

“Salting” is a common technique used to resolve this. By adding a random integer (the “salt”) to the join key in the skewed table and replicating the corresponding keys in the other table, the data is forced to redistribute more evenly across partitions. This breaks up the massive chunks of data that would otherwise overwhelm a single executor.
Financial and Operational Impact
The implications of these optimization techniques extend beyond technical performance into the realm of financial management. As enterprises move toward consumption-based pricing models in the cloud, inefficient Spark jobs directly translate to higher monthly invoices.
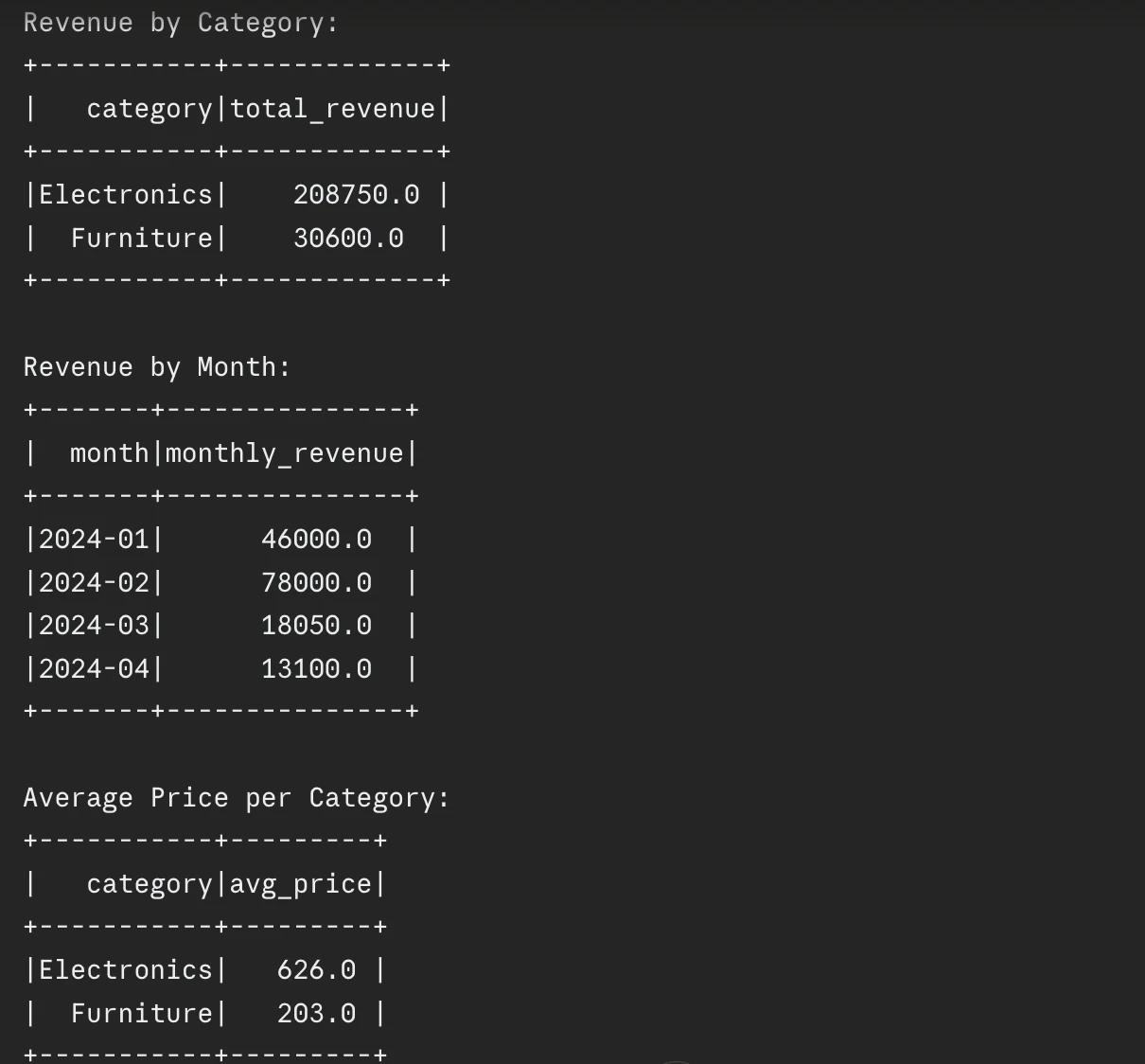
A recent analysis of cloud data spend indicates that optimized pipelines can reduce compute costs by 30% to 50%. Furthermore, faster execution times improve the “freshness” of data, allowing businesses to make decisions based on real-time or near-real-time insights rather than day-old reports.
Conclusion and Future Outlook
The evolution of Apache Spark continues to move toward increased automation and intelligence. While features like Adaptive Query Execution have lowered the barrier to entry for high-performance computing, the role of the data engineer remains critical in architecting the initial storage layers and choosing the correct high-level strategies.
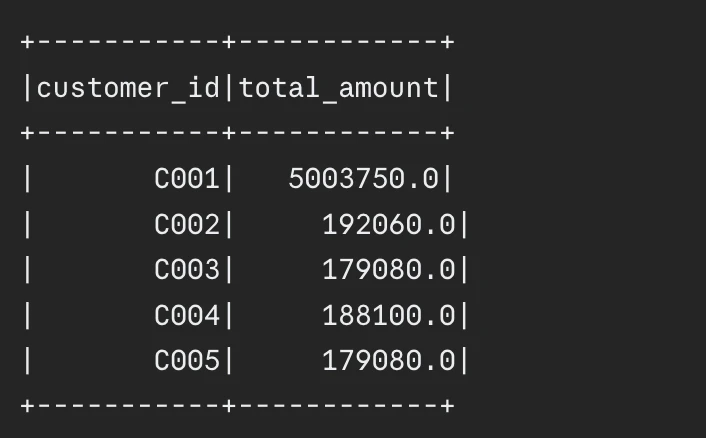
By systematically applying these 12 techniques—prioritizing columnar storage, minimizing shuffles, and leveraging modern Spark 3.x features—organizations can transform their data infrastructure from a cost center into a high-speed engine for innovation. As data volumes continue their exponential growth, the mastery of PySpark optimization will remain a defining skill for the next generation of data professionals.