The rapid advancement of artificial intelligence has transitioned from simple predictive models to complex autonomous agents capable of executing multi-step tasks. At the heart of this evolution is the development of sophisticated memory systems that allow these agents to transcend the limitations of stateless processing. Memory is the foundational element that shapes how humans perceive the world and, increasingly, how AI agents interact with users. Without a robust memory layer, an AI agent is restricted to responding only to the immediate input provided; with it, the agent can maintain context, recall past successes or failures, and apply specialized knowledge across disparate sessions.

In the current landscape of large language models (LLMs), memory is not an inherent feature of the model itself but a separate architectural layer designed by engineers. While an LLM possesses vast "parametric memory" acquired during its initial training, it lacks "functional memory"—the ability to remember a specific user’s preferences or the details of a conversation that occurred five minutes ago. To bridge this gap, developers are drawing from cognitive science to create tiered memory patterns, categorized into short-term, episodic, semantic, and long-term memory. This architectural shift is transforming AI from a simple query-response tool into a persistent digital collaborator.
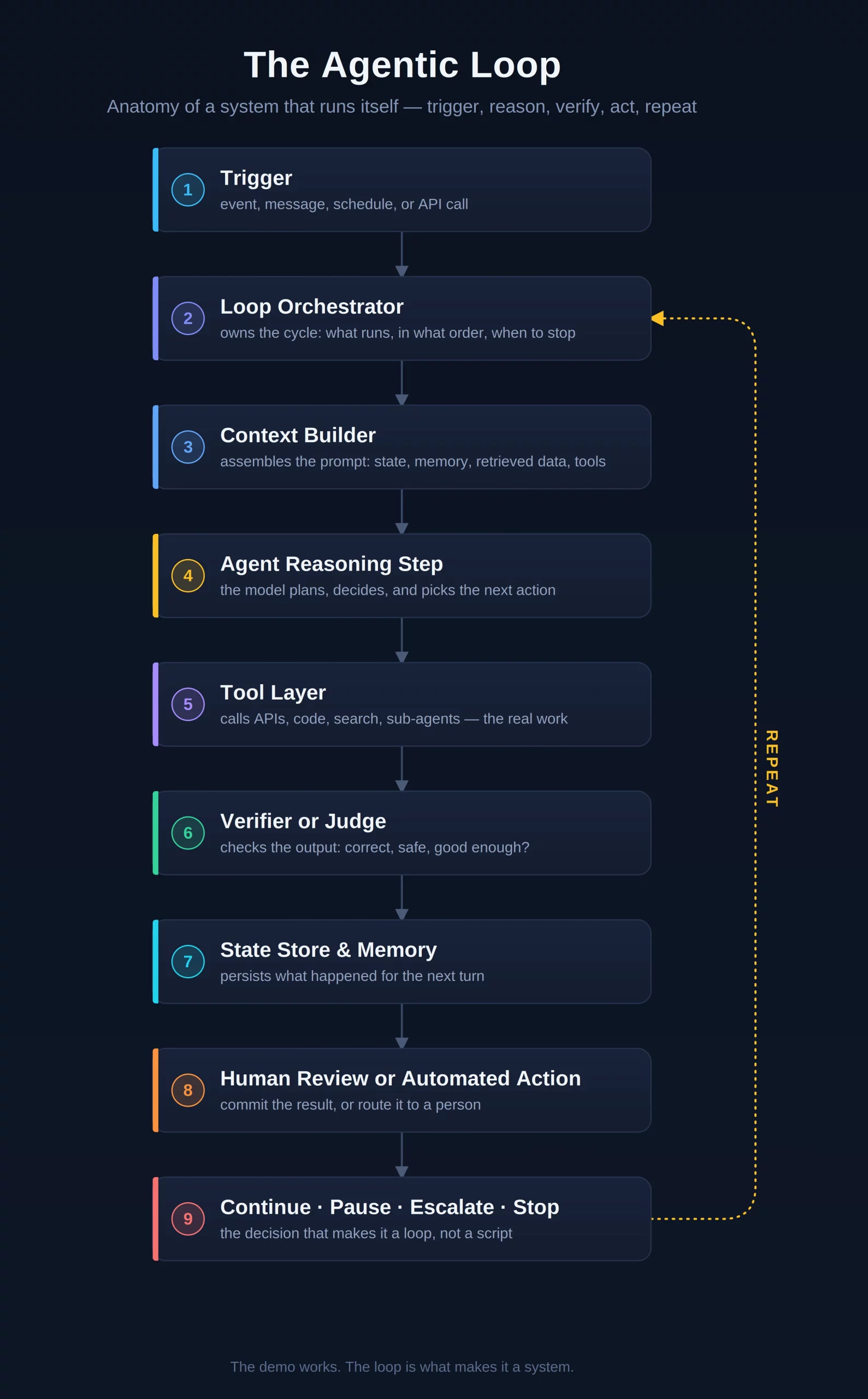
The Taxonomy of AI Agent Memory
To understand the engineering requirements of modern AI, one must first examine the four primary memory types derived from cognitive psychology. Each serves a distinct purpose in the lifecycle of an autonomous agent.

Short-term memory, often referred to as working memory, is the most immediate layer. In the context of AI, this usually involves the "context window"—the finite amount of text a model can process at one time. It is used to maintain the flow of a single conversation, ensuring that if a user says "it" in a follow-up sentence, the agent understands what "it" refers to based on the previous message.
Episodic memory involves the recording of specific events and sequences. For an AI agent, this means storing a history of past interactions, including the specific inputs, outputs, and tool calls made during a task. This is critical for traceability and for the agent to learn from its own history. If an agent previously attempted to deploy code and failed due to a specific permission error, episodic memory allows it to recall that failure and try a different approach in the future.
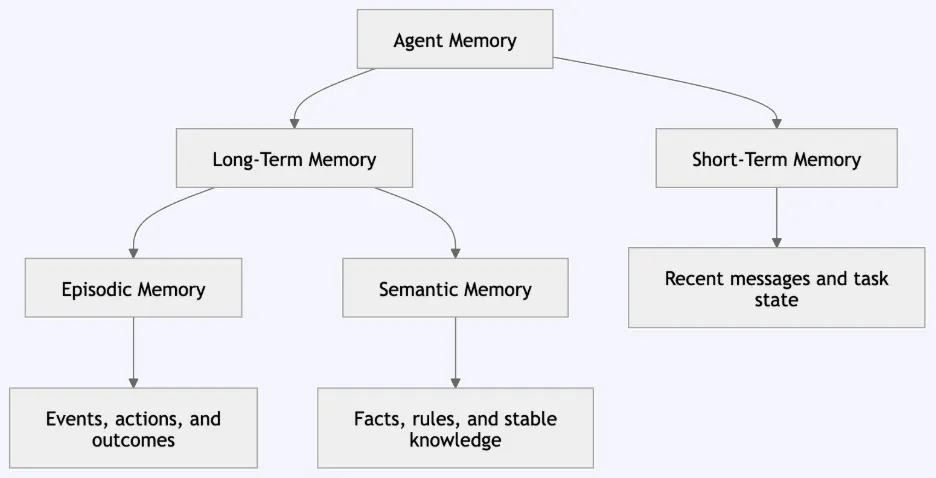
Semantic memory focuses on the storage of facts, rules, and concepts. This is the "knowledge base" of the agent. Unlike episodic memory, which is a log of events, semantic memory is structured information. For an enterprise deployment assistant, semantic memory might include the rule that "production deployments are prohibited on Fridays without executive approval." This information is stored as a reusable fact that the agent can apply to any relevant query, regardless of when it was learned.
Long-term memory acts as the overarching repository that ensures information persists across different sessions and user interactions. It is the mechanism that prevents an agent from "starting from zero" every time a new thread is initiated. By integrating these four types, developers can create agents that exhibit a sense of continuity and personalized intelligence.
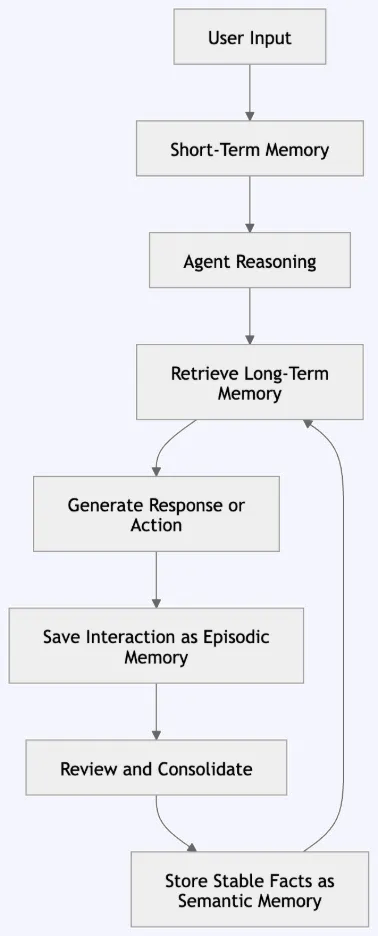
Architecture and the Lifecycle of Information
The implementation of memory in AI systems requires a structured data flow that moves information through various stages: input, retrieval, reasoning, response, and storage. This pipeline ensures that the agent remains grounded in reality while minimizing the "noise" that can occur when too much irrelevant data is fed into the model’s context window.
The process begins when a user submits a query. Before the LLM generates a response, the system queries its memory layers. It checks short-term memory for immediate context and searches semantic and episodic memory for relevant facts or past experiences. This retrieval process often utilizes vector databases, which allow the system to find information based on mathematical similarity rather than just keyword matching.

Once the relevant memories are retrieved, they are injected into the model’s prompt as "context." The agent then performs reasoning, combining the new input with the recalled information to produce a grounded response. The final, and perhaps most crucial, step is the "write" phase. After the interaction is complete, the system determines what parts of the exchange are worth keeping. An episodic log is created for the event, and if the user provided a new rule or fact, the semantic memory is updated. This ensures the system evolves with every interaction.
Technical Implementation: The LangGraph Framework
Industry experts are increasingly turning to specialized frameworks like LangGraph to manage these complex memory states. LangGraph allows for the creation of stateful, multi-actor applications by defining a graph where each node represents a function or an agent step.
In a standard implementation, such as a deployment assistant, the agent is configured with two primary storage components: a "checkpointer" and a "memory store." The checkpointer is responsible for short-term memory, saving the state of a specific thread so the conversation can continue seamlessly. The memory store handles long-term episodic and semantic data, often utilizing embeddings—numerical representations of text—to facilitate similarity searches.
For example, when a user informs an agent, "My service is the api-gateway," the agent saves this to its short-term thread. If the user later adds, "Remember that production deployments on Fridays require SRE approval," the agent recognizes the "Remember that" trigger and promotes this information to semantic memory. In future sessions, even in a completely different conversation thread, if the user asks, "Can I deploy today?" on a Friday, the agent will retrieve the SRE approval rule from its semantic store and provide a restricted, context-aware answer.

Storage Backends and Infrastructure Requirements
The choice of storage backend is a critical decision in AI engineering, as different memory types have different performance requirements.
| Memory Type | Recommended Backend | Justification |
|---|---|---|
| Short-term | Redis, In-memory, Postgres Checkpointer | Requires ultra-low latency for active conversations. |
| Episodic | MongoDB, SQLite, PostgreSQL | Optimized for logging sequential events and timestamps. |
| Semantic | Chroma, FAISS, Pinecone, pgvector | Requires vector search capabilities for similarity-based retrieval. |
| Long-term | Managed Cloud Databases (AWS RDS, Google Cloud SQL) | Focuses on durability and cross-session persistence. |
Engineers must also implement "user separation" within these backends. In a multi-tenant environment, it is vital that the memory of User A does not leak into the responses provided to User B. This is typically managed through namespace isolation, where every memory entry is tagged with a unique user_id or org_id.

Security, Privacy, and Ethical Governance
While memory enhances utility, it introduces significant risks regarding data privacy and system integrity. Storing information across sessions increases the "attack surface" for prompt injection and data leakage. If an agent inadvertently saves a password, API key, or sensitive personal identifiable information (PII) into its long-term memory, that data could be retrieved and exposed in a future, unrelated interaction.
Furthermore, "memory poisoning" is a growing concern. This occurs when a user provides false or malicious information that the agent then adopts as a "fact" in its semantic memory. If a user tells a medical AI agent that "bleach is a cure for the common cold," and the agent saves this as a semantic rule, it could provide life-threatening advice to future users.

To mitigate these risks, organizations are implementing strict governance protocols:
- Sensitive Data Filtering: Automated scripts that scrub PII and secrets before they are committed to long-term storage.
- Validation Layers: Human-in-the-loop or secondary model checks to verify the accuracy of "facts" before they are added to semantic memory.
- TTL (Time-to-Live) Policies: Automatic deletion of episodic memories after a certain period to comply with data minimization principles (e.g., GDPR).
- User-Controlled Deletion: Providing users with the ability to view, edit, or wipe their stored memory, similar to clearing browser history.
The Broader Impact on the AI Landscape
The shift toward memory-augmented agents represents a fundamental change in how humans interact with technology. We are moving away from "disposable" interactions toward "cumulative" relationships with AI. In a corporate setting, an agent with episodic and semantic memory becomes a repository of institutional knowledge, remembering why certain decisions were made months prior.

Industry analysts suggest that the market for agentic AI will hinge on the reliability of these memory systems. According to recent technical surveys, developers cite "maintaining context" and "retrieving relevant history" as the top two challenges in deploying production-ready agents. As memory architectures become more standardized, we can expect AI agents to take on more significant roles in project management, software development, and personalized education.
In conclusion, agent memory is not merely a feature of modern AI; it is the infrastructure of digital intelligence. By meticulously designing layers that mirror cognitive functions—short-term, episodic, semantic, and long-term—engineers are creating systems that do more than process data; they learn, adapt, and remember. However, the power of memory must be balanced with rigorous governance to ensure that these digital minds remain safe, private, and grounded in truth. As we look toward the future, the agents that succeed will be those that can most effectively bridge the gap between human-like recall and machine-scale efficiency.