The global artificial intelligence landscape has reached a new inflection point with Google’s official introduction of the Gemini 3.5 family, spearheaded by the immediate release of Gemini 3.5 Flash. This latest iteration of Google’s proprietary large language model (LLM) architecture represents a strategic shift in the company’s approach to generative AI, prioritizing not just the raw intelligence of its models, but the speed, cost-efficiency, and “agentic” capabilities required for real-world enterprise deployment. While the more computationally intensive Gemini 3.5 Pro is slated for a release in the coming month, the Flash variant has been positioned as the workhorse of the ecosystem, designed to bridge the gap between high-level frontier intelligence and the low-latency requirements of modern digital workflows.
The Evolution of the Gemini Ecosystem
To understand the significance of Gemini 3.5 Flash, it is essential to view it within the broader chronology of Google’s AI development. Following the rebranding of Bard to Gemini and the subsequent rollout of the Gemini 1.5 architecture—which introduced the industry-leading one-million-token context window—Google has been under pressure to optimize these capabilities for speed and cost.

The “Flash” series was originally conceived to serve developers who required the multimodal reasoning of the Pro models but could not afford the latency or the price point associated with massive parameter counts. Gemini 3.5 Flash is the culmination of this optimization strategy. It is not merely a “shrunk” version of its predecessors but a rebuilt engine designed specifically for long-horizon task handling, collaborative subagent orchestration, and large-scale automation.
Core Technical Specifications and Capabilities
Gemini 3.5 Flash distinguishes itself through several key pillars of functionality that separate it from both the previous 1.5 Flash and its current market competitors, such as OpenAI’s GPT-4o-mini and Anthropic’s Claude 3.5 Haiku.
1. Agentic Workflow Support
One of the most touted features of the 3.5 architecture is its “agentic” nature. Unlike traditional LLMs that act as passive chat interfaces, Gemini 3.5 Flash is built to function as an autonomous or semi-autonomous agent. This includes the ability to break down complex prompts into smaller, manageable sub-tasks, which can then be delegated to “subagents.” For example, in a software development environment, the model can simultaneously manage code generation, documentation, and unit testing as distinct but interconnected workflows.
2. Enhanced Multimodal Reasoning
While text-based processing remains a core strength, Gemini 3.5 Flash excels in multimodal environments. It can process and reason across text, images, video, and audio with a level of synchronization that reduces the “hallucination” rate often seen when models attempt to describe visual data. This makes it particularly effective for industries like media production, where users might need to search through hours of video footage using natural language queries.
3. Low-Latency Performance
In the realm of AI, latency is the enemy of user experience. Google has optimized the inference path for Gemini 3.5 Flash to ensure that response times remain consistently low, even when handling large context windows. This is critical for applications such as real-time customer service bots, live translation services, and interactive gaming environments where a delay of even a few seconds can break the utility of the tool.
Empirical Performance: Hands-On Testing and Logic Benchmarks
Initial testing of Gemini 3.5 Flash reveals a model that is significantly more “grounded” in physical and logical reality than previous iterations. Several “hands-on” scenarios demonstrate its practical utility.
Rapid Prototyping and Frontend Development
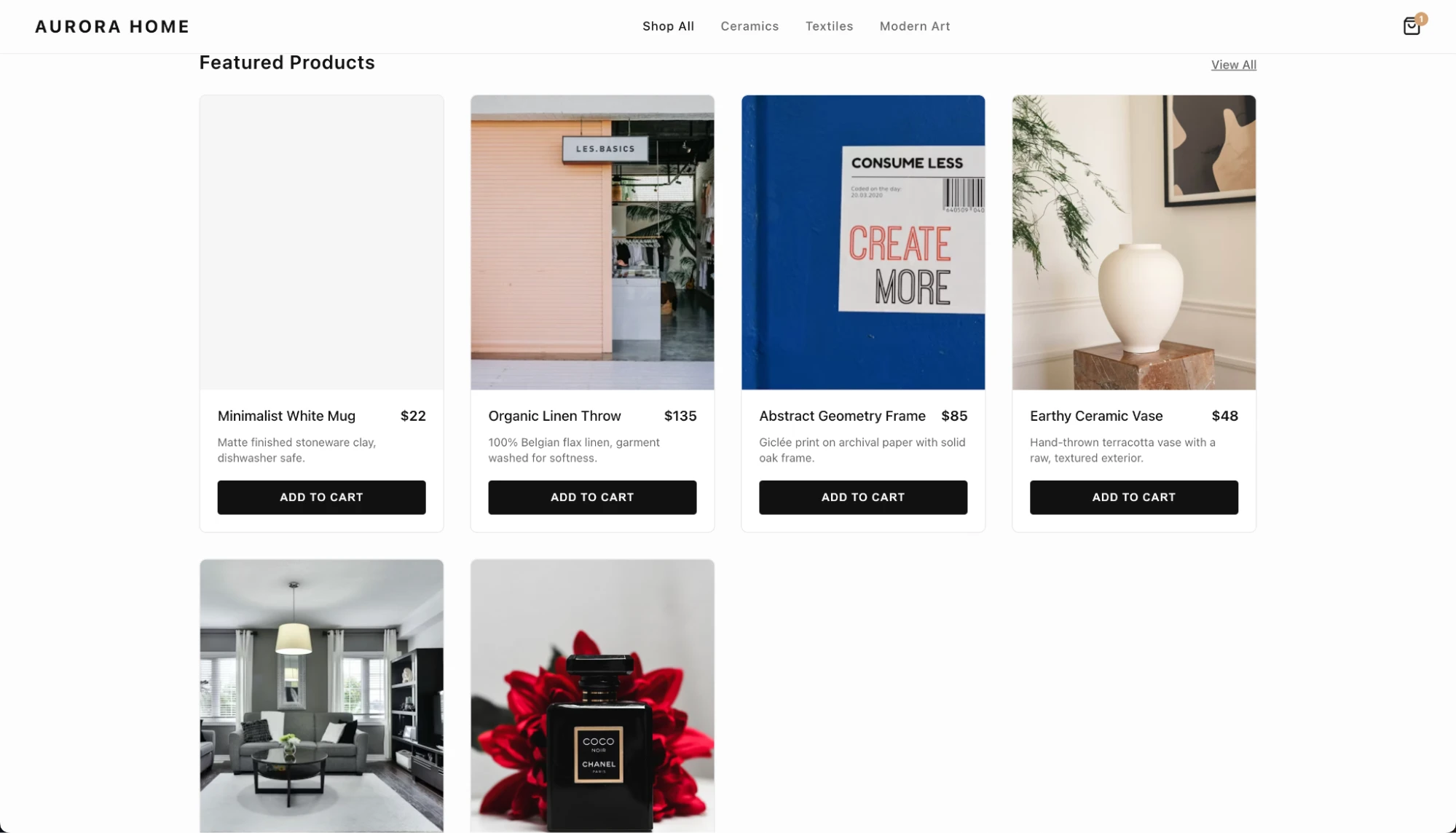
In a test involving the generation of a modern e-commerce frontend using only HTML and inline CSS, Gemini 3.5 Flash produced a functional, visually coherent interface in under 10 seconds. While the output required minor refinements—such as the integration of functional buttons and external image hosting—the speed at which the model structured the layout, color schemes, and navigation bars provides a significant advantage for developers looking to move from concept to wireframe instantly.
Solving the “Car Wash” Logic Puzzle
A common benchmark for testing the “common sense” of an LLM is the car wash problem: “I want to wash my car. The car wash is 50 meters away. Should I walk or drive?” Older models and many contemporary competitors have historically struggled with this, often suggesting the user “walk” because 50 meters is a short distance, failing to realize that the object being washed—the car—must be present at the car wash. Gemini 3.5 Flash correctly identifies the spatial and logical requirement to drive the vehicle to the facility, signaling a deeper understanding of physical constraints and objectives.
Visual Decay and Multimodal Synthesis
To test its ability to process complex scientific and technical concepts visually, the model was tasked with demonstrating “JPEG decay”—the phenomenon where an image loses quality after being compressed and saved multiple times. The model was able to generate a gradient visualization showing the transition from a high-resolution original to a 20th-generation compressed file. This task requires the model to understand the technical physics of data loss and translate that into a visual representation, a feat it accomplished within the Gemini App’s AI Mode in a matter of seconds.
Strategic Market Positioning and Accessibility
Google is making Gemini 3.5 Flash available across a wide array of platforms to ensure maximum penetration in the developer and enterprise markets. Currently, the model can be accessed through:
- Gemini App: Available for consumer-level interactions and quick tasks.
- Google AI Studio: A web-based tool for developers to prototype with the Gemini API.
- Vertex AI: Google Cloud’s enterprise-grade platform for building and deploying machine learning models at scale.
Notably, Gemini 3.5 Flash remains a closed-weights model, accessible only via API. For users and organizations requiring local execution or open-source flexibility, Google points toward the Gemma 4 family of models. This distinction allows Google to maintain a tiered ecosystem: Gemma for open-source local needs, Flash for high-speed cloud-based efficiency, and Pro for maximum-depth reasoning.
Industry Implications and the Competitive Landscape
The release of Gemini 3.5 Flash is a direct response to the aggressive release cycles of OpenAI and Anthropic. By focusing on “Flash” first, Google is targeting the highest-volume segment of the AI market: developers who need reliable, fast, and cheap intelligence.

Industry analysts suggest that the “intelligence-per-dollar” metric is becoming the most important factor for enterprise AI adoption. While “frontier” models like GPT-4 or Gemini Ultra grab headlines for their complexity, the vast majority of commercial use cases—such as data extraction, content summarization, and basic coding assistance—do not require the full power of a flagship model. By providing a model that is “smart enough” for 90% of tasks but significantly faster and cheaper, Google is attempting to lock in enterprise clients before the next generation of flagship models arrives.
Furthermore, the integration of Gemini 3.5 Flash into the Google Workspace and Google Cloud ecosystems provides a seamless transition for businesses already utilizing Google’s infrastructure. The ability to use Flash to scan thousands of emails, summarize massive Spreadsheets, or generate internal documentation in seconds represents a tangible productivity gain that is easy for corporate leadership to quantify.
Chronology of Recent Google AI Milestones
- February 2024: Introduction of Gemini 1.5 Pro with a 128,000-token context window (later expanded to 1 million).
- April 2024: Launch of TurboQuant, a technique to reduce model memory usage by half, signaling Google’s focus on efficiency.
- May 2024: Announcement of the Gemini 3.5 family during the Google I/O keynote.
- Current: Release of Gemini 3.5 Flash to the general public and developers via API and Vertex AI.
- Upcoming Month: Scheduled release of Gemini 3.5 Pro, expected to set new benchmarks in multimodal complexity and coding.
Final Verdict and Future Outlook
Gemini 3.5 Flash represents a “maturation” of generative AI. The industry is moving away from the novelty of chatting with a bot and toward the utility of integrating AI into the plumbing of the internet. The speed of Gemini 3.5 Flash is its most transformative feature; by reducing the time-to-first-token to near-instantaneous levels, Google has made AI feel less like a remote server and more like a local component of the user’s operating system.

While the quality of responses in highly creative or deeply philosophical tasks may still lean in favor of the upcoming Pro or Ultra variants, the Flash model’s performance in logic, rapid coding, and multimodal synthesis proves that it is more than capable of handling the heavy lifting of modern digital life. As the AI “arms race” continues, Google’s focus on the “Flash” tier may well be the strategy that secures its dominance in the enterprise sector, providing the necessary speed for a world that refuses to wait.