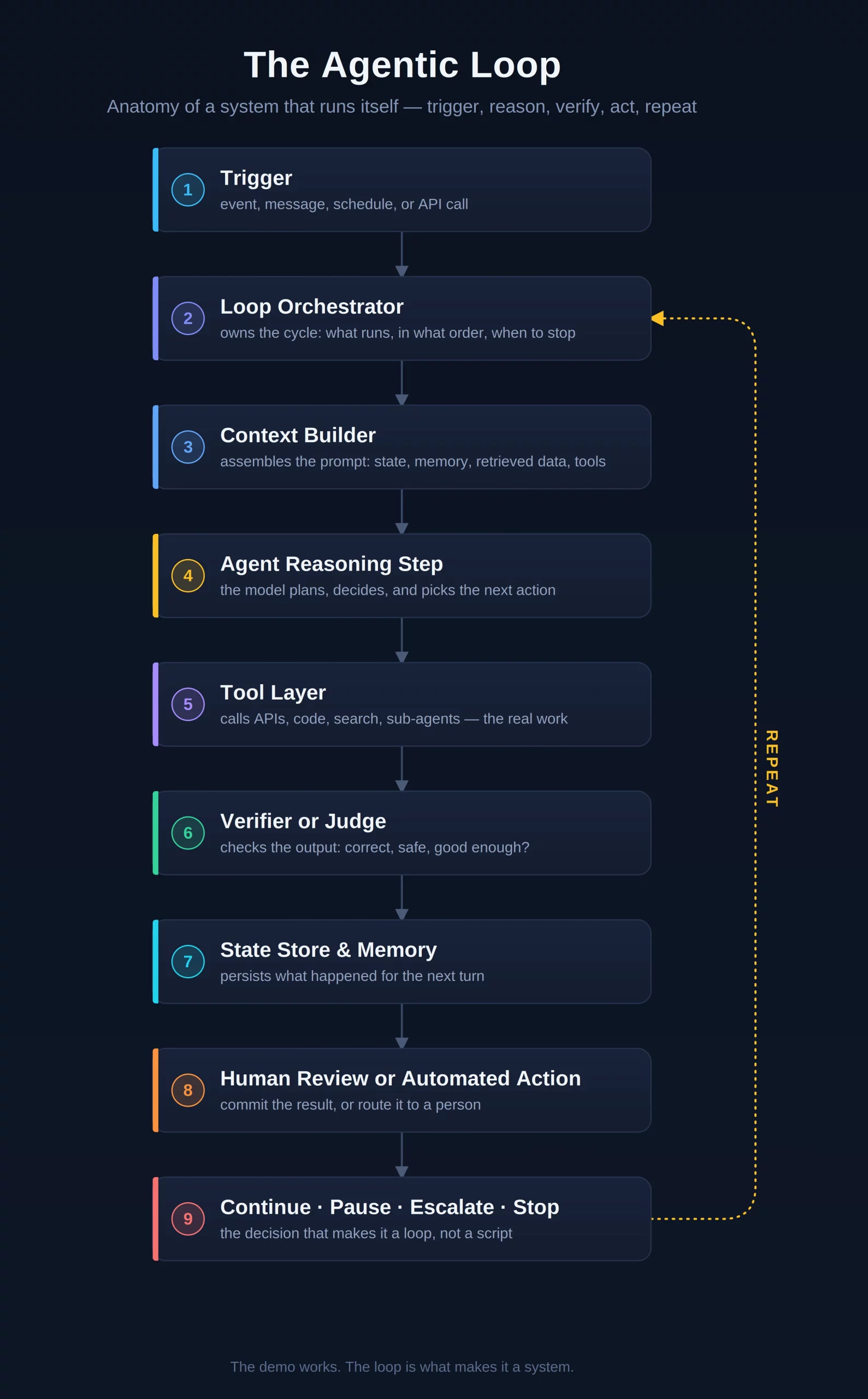
The landscape of artificial intelligence is undergoing a fundamental shift from text-based interactions toward fluid, naturalistic voice communication. While the initial wave of generative AI relied heavily on the "prompt and wait" cycle of text entry, the next frontier is defined by real-time auditory reasoning. OpenAI has signaled its intent to lead this transition by introducing a suite of three new models within its Realtime API: GPT-Realtime-2, GPT-Realtime-Translate, and GPT-Realtime-Whisper. These models are designed to dismantle the latency barriers that have historically made voice AI feel robotic and disjointed, offering developers the tools to build applications that can listen, process, and respond with the cadence of a human interlocutor.
The Technical Evolution of Voice AI Architecture
To understand the significance of OpenAI’s latest release, one must first examine the limitations of traditional voice AI systems. Historically, voice interaction was a multi-stage "cascade" process. When a user spoke, the system first utilized a Speech-to-Text (STT) model to transcribe the audio into a text string. This text was then fed into a Large Language Model (LLM) to generate a response. Finally, a Text-to-Speech (TTS) engine converted that response back into audio. While effective for simple commands, this relay-race architecture introduced significant latency, often resulting in a three-to-five-second delay. Furthermore, because the LLM only "saw" the text, it lost the nuances of human speech, such as tone, inflection, and emotional subtext.
The new generation of real-time models moves toward a native multimodal approach. By processing audio streams directly and reasoning through them as they arrive, OpenAI’s new models reduce the "time to first byte" of audio response to a fraction of a second. This allows for "duplex" communication, where the AI can be interrupted mid-sentence, handle pauses gracefully, and adjust its reasoning based on the speaker’s tone. This shift is not merely a technical upgrade; it represents a move toward AI that can participate in the social dynamics of human conversation.
A Chronology of OpenAI’s Audio Innovation
The release of the GPT-Realtime suite is the culmination of several years of iterative development at OpenAI. The journey began in September 2022 with the release of Whisper, an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data. Whisper set a new standard for transcription accuracy but was primarily designed for asynchronous processing—transcribing pre-recorded files rather than live speech.
In 2023, OpenAI introduced voice capabilities to the ChatGPT mobile app, utilizing a more advanced version of the traditional STT-LLM-TTS pipeline. However, the true turning point occurred in May 2024 with the announcement of GPT-4o ("o" for "omni"). This was the first model built from the ground up to be natively multimodal, meaning it could process text, audio, and images within a single neural network. The subsequent launch of the Realtime API in late 2024 allowed developers to tap into these low-latency capabilities. The current introduction of GPT-Realtime-2, Translate, and Whisper represents the maturation of this technology, providing specialized versions of the "omni" architecture for specific commercial and industrial tasks.
Detailed Breakdown of the New Model Suite
The new release bifurcates the Realtime API into three distinct specializations, each addressing a specific bottleneck in global communication and workflow automation.
GPT-Realtime-2: The Conversational Engine
GPT-Realtime-2 serves as the flagship model for interactive agents. Unlike its predecessors, this model features an expanded context window of 128,000 tokens—a fourfold increase from the previous 32,000-token limit. In practical terms, this allows the AI to maintain the thread of a conversation over hours rather than minutes. This is critical for complex use cases such as technical support or medical consultations, where the AI must remember details mentioned at the start of a long interaction.
Furthermore, GPT-Realtime-2 introduces "stronger recovery behavior." In earlier iterations, if a user interrupted the AI or changed the subject abruptly, the model might experience a "hallucination" or a logic break. The new architecture is specifically tuned to handle the messy reality of human speech, including stutters, self-corrections, and background noise.
GPT-Realtime-Translate: Breaking the Language Barrier
Translation has traditionally been a "stop-and-start" process. GPT-Realtime-Translate aims to achieve the "Universal Translator" concept popularized in science fiction. It is capable of taking speech in one of over 70 input languages and translating it into 13 output languages with near-zero lag.
The breakthrough here is the model’s ability to begin translating a sentence before the speaker has even finished it. By predicting the likely conclusion of a phrase based on context, the model provides a stream of translated audio that keeps pace with the original speaker. This has profound implications for international diplomacy, global business negotiations, and live broadcasting.
GPT-Realtime-Whisper: Synchronous Transcription
While the original Whisper was a revolutionary tool for archivists and journalists, GPT-Realtime-Whisper is built for the "now." It provides live, word-for-word transcription that appears on-screen as the speaker talks. This is achieved through a streaming architecture that processes audio chunks in milliseconds. For accessibility, this means high-accuracy live captioning for the hearing impaired. For the enterprise, it means meeting minutes that are generated and indexed in real-time, allowing participants to search for a term mentioned only moments prior.
Supporting Data and Performance Metrics
OpenAI’s push into real-time audio is backed by significant improvements in model efficiency and cost-effectiveness. Internal benchmarks suggest that GPT-Realtime-2 offers a 30% reduction in "perceived latency" compared to the original Realtime API preview.
The expansion of the context window to 128K tokens is perhaps the most significant data point for enterprise developers. In a standard customer service call, 32K tokens could be exhausted in roughly 20 to 30 minutes of dense dialogue. With 128K tokens, the model can sustain conversations lasting several hours while still being able to "recall" specific data points, such as a tracking number or a specific symptom, mentioned at the beginning of the call.
Additionally, the models now support "Reasoning Effort" settings. Developers can choose between "Low," "Medium," and "High" reasoning levels. This allows for cost optimization: a simple task like booking a hair appointment requires low reasoning effort and thus costs less, whereas a model acting as a legal research assistant can be set to high reasoning to ensure maximum accuracy and logical consistency.
Broader Implications and Industry Impact
The deployment of these models is expected to disrupt several multi-billion-dollar industries. In the customer experience (CX) sector, the "automated phone tree" is likely to be replaced by empathetic, fast-acting voice agents. Unlike current automated systems that often frustrate users with slow responses and limited understanding, GPT-Realtime-2 can access external tools—such as a company’s database—to process refunds or change flight details while the conversation is ongoing.
In healthcare, these models can act as "ambient scribes." A physician can conduct an exam while GPT-Realtime-Whisper transcribes the interaction and GPT-Realtime-2 summarizes the key findings into a patient’s electronic health record. This reduces the administrative burden on medical staff, which is currently a leading cause of professional burnout.
However, the rise of hyper-realistic, real-time voice AI also brings significant ethical challenges. The ability of these models to mimic human tone and emotion increases the risk of sophisticated "vishing" (voice phishing) attacks. OpenAI has addressed these concerns by implementing strict safety filters that prevent the models from generating certain types of sensitive or harmful content. Furthermore, developers using the API are required to disclose to users that they are interacting with an AI, a move supported by various international AI safety frameworks, including the EU AI Act.
Official Responses and Market Context
While OpenAI has not released specific client testimonials alongside this launch, the broader tech ecosystem has responded with a mixture of enthusiasm and caution. Competitors such as Google, with its Gemini Multimodal Live API, and startups like ElevenLabs are also racing to dominate the voice space. Industry analysts suggest that OpenAI’s advantage lies in its integrated ecosystem; by offering transcription, translation, and reasoning within a single API, they reduce the complexity for developers who would otherwise have to "stitch together" services from multiple providers.
A spokesperson for a leading Silicon Valley venture capital firm noted that "the move from text-based AI to voice-based AI is equivalent to the move from the command-line interface to the graphical user interface. it makes the technology accessible to the 100% of the population that can speak, rather than just the percentage that is comfortable with precise text prompting."
Conclusion: The Path Toward Active Assistance
The introduction of GPT-Realtime-2, Translate, and Whisper marks the end of the "passive" era of AI. We are moving away from systems that merely respond to prompts and toward "Active Assistants" that can participate in the world in real-time. By enabling AI to listen and speak with human-like fluidity, OpenAI is not just improving a product; it is redefining the interface through which humanity interacts with digital intelligence.
As these models move out of the Playground and into consumer-facing applications, the focus will shift toward refinement. Developers will need to balance the power of these models with robust guardrails to ensure privacy and security. Nevertheless, the trajectory is clear: the future of AI is no longer a silent one. It is a future where the most powerful tool in the world is one that we can simply talk to, and which, for the first time, truly understands us in the moment.