The landscape of digital marketing has undergone a radical transformation over the past decade, shifting from a discipline rooted in creative intuition to one increasingly dominated by data-driven decision-making. At the heart of this shift lies A/B testing—a methodology that, in theory, represents the highest potential for applying scientific principles to business growth. By utilizing randomized controlled trials (RCTs), digital practitioners can mirror the rigorous experimental standards found in fields such as physics, genetics, and clinical medicine. However, a growing consensus among statisticians suggests that the current industry standards for A/B testing are lagging significantly behind modern scientific practices. Many of the statistical frameworks utilized by today’s marketing teams are based on concepts that have been superseded in other scientific disciplines for over half a century, leading to a phenomenon where business decisions are frequently built upon a foundation of illusory data.
The discrepancy between professional practice and statistical reality stems from a fundamental misunderstanding of classical frequentist statistics. While A/B testing is marketed as a "plug-and-play" solution for optimizing conversion rates, the underlying mathematics require strict adherence to protocols that are often ignored in high-pressure corporate environments. Industry experts have identified three primary systemic issues: the misuse of statistical significance tests, a widespread disregard for statistical power, and the inherent inefficiency of classical "fixed-sample" testing models when applied to the fast-moving digital economy.
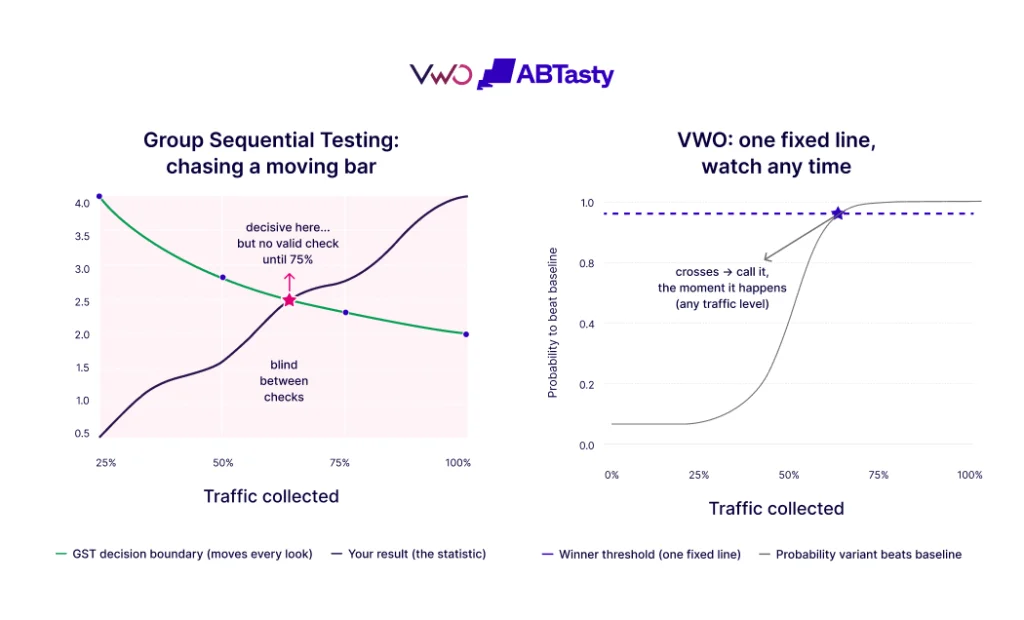
The Pitfalls of "Data Peeking" and Significance Inflation
In the standard nomenclature of A/B testing, "statistical significance" is often treated as a finish line. When a dashboard shows a 95% confidence level, many practitioners immediately declare a winner and terminate the experiment. This practice, however, violates a core assumption of the Student’s T-test and other classical frequentist methods: the requirement of a fixed sample size determined in advance.
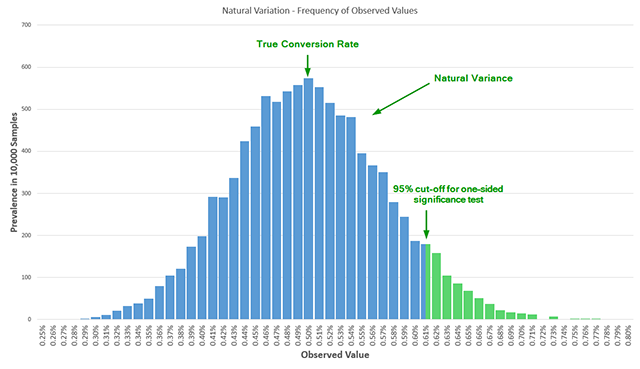
A statistical significance test is essentially an estimate of the probability that an observed result—such as a 10% lift in conversions—occurred due to random variance rather than a genuine change in user behavior. In a Bernoulli distribution, which models binary outcomes like "converted" or "did not convert," natural variance is a constant factor. If an experimenter observes data at a single, pre-determined point in time after reaching a required sample size, the reported error rate remains accurate.
The crisis arises from "data-driven optional stopping," commonly known as peeking. In a corporate setting, stakeholders often monitor real-time dashboards. If a variant shows a strong positive trend after three days, there is immense pressure to stop the test and "capture the revenue." Conversely, if a variant performs poorly, teams want to "cut their losses" early. Mathematically, every time a practitioner "peeks" at the data to make a decision, they introduce a new dimension into the test’s sample space. Without adjusting for these multiple looks, the probability of a false positive increases exponentially. Research indicates that peeking just five times during a test can more than triple the actual error rate compared to the nominal error rate reported by the software. By the tenth peek, the risk of declaring a "winner" that is actually a product of random noise is five times higher than the practitioner believes. This "Garbage In, Garbage Out" (GIGO) cycle leads companies to implement changes that provide no real value, or worse, actively harm their long-term conversion rates.
The Invisible Problem of Statistical Power
While significance (Alpha) focuses on avoiding false positives, statistical power (Beta) focuses on avoiding false negatives. In the context of digital experimentation, power is the sensitivity of a test—the probability that it will detect a true lift of a certain magnitude if one actually exists. Despite its importance, a meta-analysis of influential A/B testing literature published between 2008 and 2014 revealed that only a small fraction of resources even mentioned the concept of power, and even then, only superficially.
Running an under-powered test is equivalent to using a low-resolution microscope to look for bacteria; if you don’t see anything, it doesn’t mean the bacteria aren’t there—it means your equipment wasn’t sensitive enough to find them. Many free A/B testing calculators operate at a default power of 50%, which is essentially a coin toss. This lack of sensitivity results in a massive waste of organizational resources. Teams may spend weeks designing and implementing a new checkout flow, only to discard it because an under-powered test failed to "prove" its efficacy. This leads to a "chilling effect" where innovative ideas are abandoned based on flawed negative results, barring the company from pursuing directions that could have yielded significant gains.
The Efficiency Gap in Classical Testing Models
The third major hurdle is the inherent inefficiency of classical fixed-sample testing. These methods were originally designed for agriculture and physics, where experiments have a clear beginning and end, and the cost of monitoring data mid-stream is either impossible or irrelevant. In the digital world, however, time is a currency.
If a test is designed to reach 95% confidence and 90% power to detect a 10% lift, it might require a sample size of 100,000 users. If the true lift of the new variant is actually 20%, a classical test still requires the practitioner to wait until the full 100,000-user threshold is met before a result can be officially declared. This results in "opportunity cost," where a company continues to serve an inferior version of a website to 50% of its users long after the superiority of the new version has become statistically evident.
A New Framework: The AGILE Statistical Approach
To bridge the gap between 1950s statistics and 21st-century business needs, a new methodology has emerged, inspired by the rigorous protocols used in medical randomized controlled trials (RCTs). Known as the AGILE statistical approach, this framework adapts "group sequential analysis" to the world of Conversion Rate Optimization (CRO).
The AGILE method is built on three foundational improvements over classical testing:
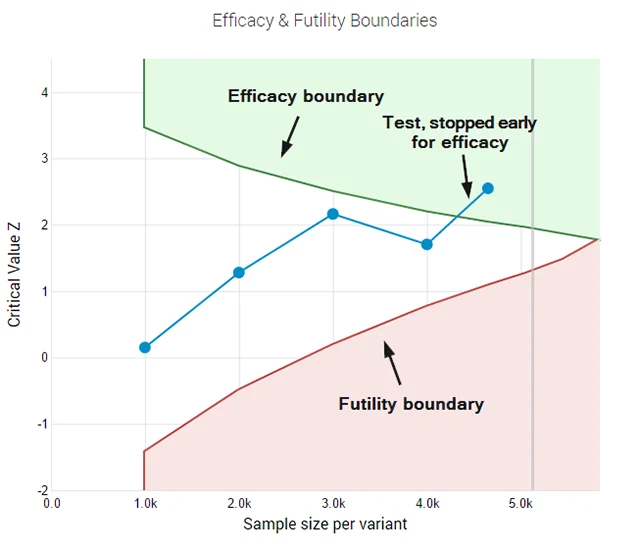
- Error-Spending Functions: Instead of requiring a single look at the end of a test, AGILE utilizes mathematical functions that "spend" the allowed error rate (Alpha) across multiple interim analyses. This allows practitioners to monitor data and stop tests early for efficacy without inflating the false-positive rate.
- Mandatory Power Consideration: The design of an AGILE test necessitates the pre-calculation of power, ensuring that every experiment is sensitive enough to detect the "Minimum Effect of Interest."
- Futility Stopping Rules: Perhaps the most significant business advantage of the AGILE method is the ability to "fail fast." Futility rules allow a practitioner to terminate a test if the early data suggests there is a very low probability of the variant ever reaching a significant positive result. This allows teams to pivot to new hypotheses weeks earlier than they would under a fixed-sample regime.
Chronology of Statistical Integration in Business
The journey toward the AGILE method follows a distinct timeline of scientific cross-pollination:
- 1920s-1930s: Ronald Fisher and the Neyman-Pearson framework establish the foundations of hypothesis testing for agriculture and biology.
- 1960s-1970s: The medical community realizes that fixed-sample tests are unethical in clinical trials; if a drug is clearly saving lives, it is wrong to continue giving a placebo to the control group. Sequential analysis methods are developed to allow for interim monitoring.
- 2000s: The "Big Data" boom leads to the democratization of A/B testing through tools like Google Website Optimizer and Optimizely. However, these tools initially prioritize user interface over statistical rigor.
- 2015-Present: The "reproducibility crisis" in social sciences and the maturation of the CRO industry lead to a demand for more robust methods, culminating in the adaptation of medical-grade sequential testing for digital platforms.
Industry Implications and Analysis
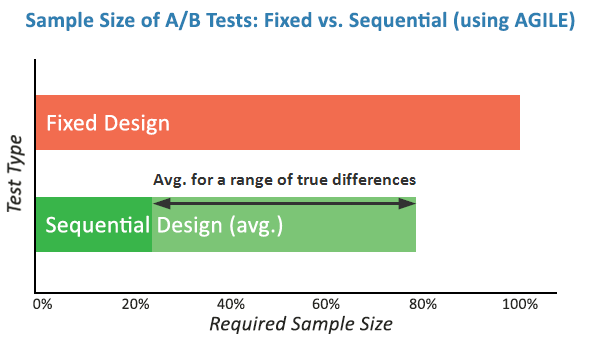
The shift toward more complex statistical models like AGILE carries profound implications for the tech industry. For large-scale enterprises, the efficiency gains are substantial. Simulations indicate that the AGILE method can reduce the required sample size by 20% to 80% when the actual lift is significantly higher than the minimum effect of interest. In a competitive market, the ability to validate five ideas in the time it previously took to validate two is a decisive advantage.
However, the adoption of these methods requires a cultural shift within organizations. It demands a move away from "vanity metrics" and toward a more disciplined, documented experimental process. Data scientists and marketing managers must collaborate more closely to set realistic parameters for significance and power before a single user is ever exposed to a test.
Ultimately, the refinement of A/B testing reflects the broader maturation of the digital economy. As the low-hanging fruit of basic web optimization is picked, companies must rely on increasingly subtle and precise measurements to find growth. By abandoning outdated statistical models in favor of frameworks like AGILE, the industry can finally align its practices with the scientific rigor it has long claimed to possess. The result will be fewer illusory wins, fewer missed opportunities, and a more genuine understanding of user behavior in an increasingly complex digital world.