The artificial intelligence industry has reached a critical inflection point where the pursuit of raw computational intelligence is no longer the primary metric of success. For the past two years, the narrative surrounding large language models (LLMs) was dominated by a relentless race to publish higher benchmark scores, increase parameter counts, and expand context windows. However, as AI integration moves from the experimental phase into core enterprise production, the priorities of developers and corporate stakeholders have fundamentally shifted. Reliability, cost-predictability, and scalability have become the new benchmarks of excellence. It is within this evolving landscape that Anthropic has launched Claude Opus 4.8, a model designed not just to think better, but to work more effectively within autonomous, high-stakes environments.
The release of Claude Opus 4.8 marks a strategic pivot for Anthropic. While the company positions the model as a significant upgrade over its predecessor, Opus 4.7, particularly in the realms of coding, complex reasoning, and agentic task execution, the most striking aspects of the announcement lie in what the model represents for the future of the industry. It signals a move away from “conversational AI”—systems designed primarily for dialogue—toward “operational AI,” or systems capable of planning, coordinating, and executing multi-stage workflows with minimal human oversight.
The Economic Equation: Stability and Scalability
In a market where frontier model upgrades often come with increased resource requirements or adjusted pricing tiers, Anthropic has opted for a strategy of price stability coupled with efficiency gains. The standard pricing for Opus 4.8 remains identical to that of Opus 4.7, a move aimed at providing enterprises with the budgetary certainty required for long-term deployment. Developers will continue to pay $5 per million input tokens and $25 per million output tokens.
However, the most significant economic update involves the “Fast Mode” tier. Anthropic has heavily incentivized high-speed execution by discounting this tier by 300% compared to previous iterations. For workflows requiring 2.5x the standard execution speed, the pricing has been set at $10 per million input tokens and $50 per million output tokens. This reduction is specifically targeted at “agentic” workflows—processes where an AI must make hundreds of rapid, sequential decisions to complete a task. By lowering the barrier to high-speed processing, Anthropic is making the operational expense of scaling complex autonomous systems far easier for CTOs and lead developers to justify.
The Honesty Upgrade: Tackling the Reliability Gap
The maturation of frontier AI models has led to a plateau in general knowledge performance; most top-tier models can now handle standard professional tasks with a high degree of competence. The true differentiator in the current market is how a model handles “edge cases”—scenarios that are ambiguous, data-poor, or highly complex.
The industry has long struggled with the “hallucination” problem, where models confidently provide incorrect information rather than admitting a lack of knowledge. With Opus 4.8, Anthropic has explicitly prioritized “honesty” as a core architectural feature. The model has undergone specific training to recognize the boundaries of its own information and to flag uncertainties to the user.

This “Honesty Upgrade” addresses one of the most persistent and expensive frustrations in AI deployment: the need for constant human verification. In a production environment, an AI that fails gracefully by stating “I am unsure” is far more valuable than one that provides a plausible but incorrect answer. By surfacing its internal uncertainty, Opus 4.8 allows developers to build more robust guardrails, ensuring that high-risk decisions are escalated to human operators rather than being handled by a hallucinating algorithm.
The Transition to Agentic Workflows and Claude Code
While the model’s internal reasoning is the engine of the release, the functional product updates accompanying Opus 4.8 reveal the broader strategic direction of the company. Alongside the model, Anthropic introduced Dynamic Workflows for Claude Code, a feature that represents a fundamental change in how AI interacts with software development.
Dynamic Workflows allow the model to autonomously plan tasks and manage hundreds of parallel “subagents” within a single session. This is a departure from the traditional linear interaction model. For example, in a large-scale codebase migration involving hundreds of thousands of lines of code, Claude Code can now initiate the project, spawn subagents to handle specific modules, execute tests to verify its own work, and manage the process through to the final merge.
To give users more granular control over these autonomous processes, Anthropic has introduced an “Effort Control” slider on Claude.ai and its Cowork platform. This allows users to dictate the processing depth the model applies to a specific task. A user might set the effort to “low” for a quick summary of a document, but slide it to “maximum” for a complex architectural review or a multi-step debugging process. This feature acknowledges that not every task requires the full cognitive load of a frontier model, allowing for better management of both time and token usage.
Comparative Testing: Reasoning and Technical Accuracy
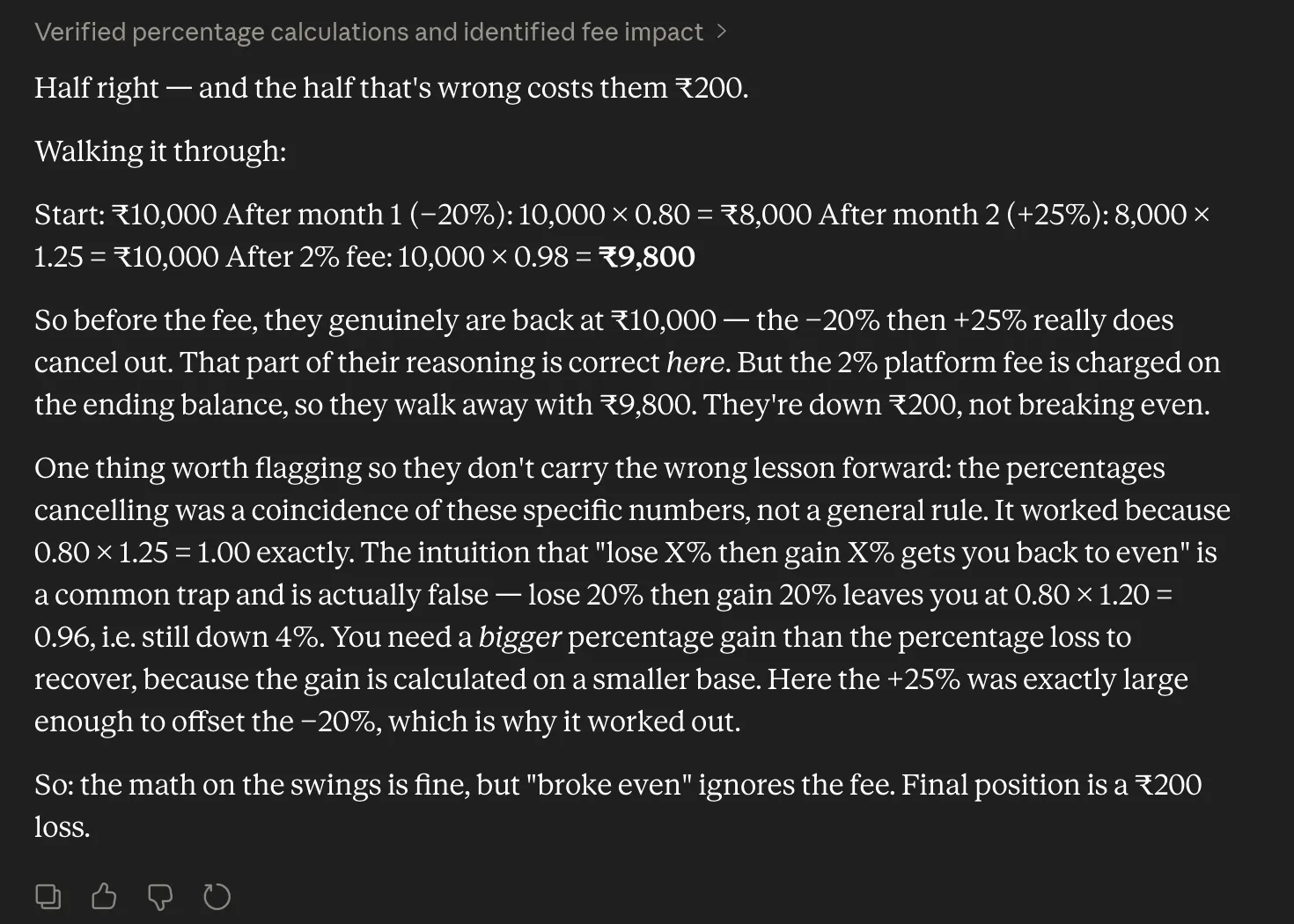
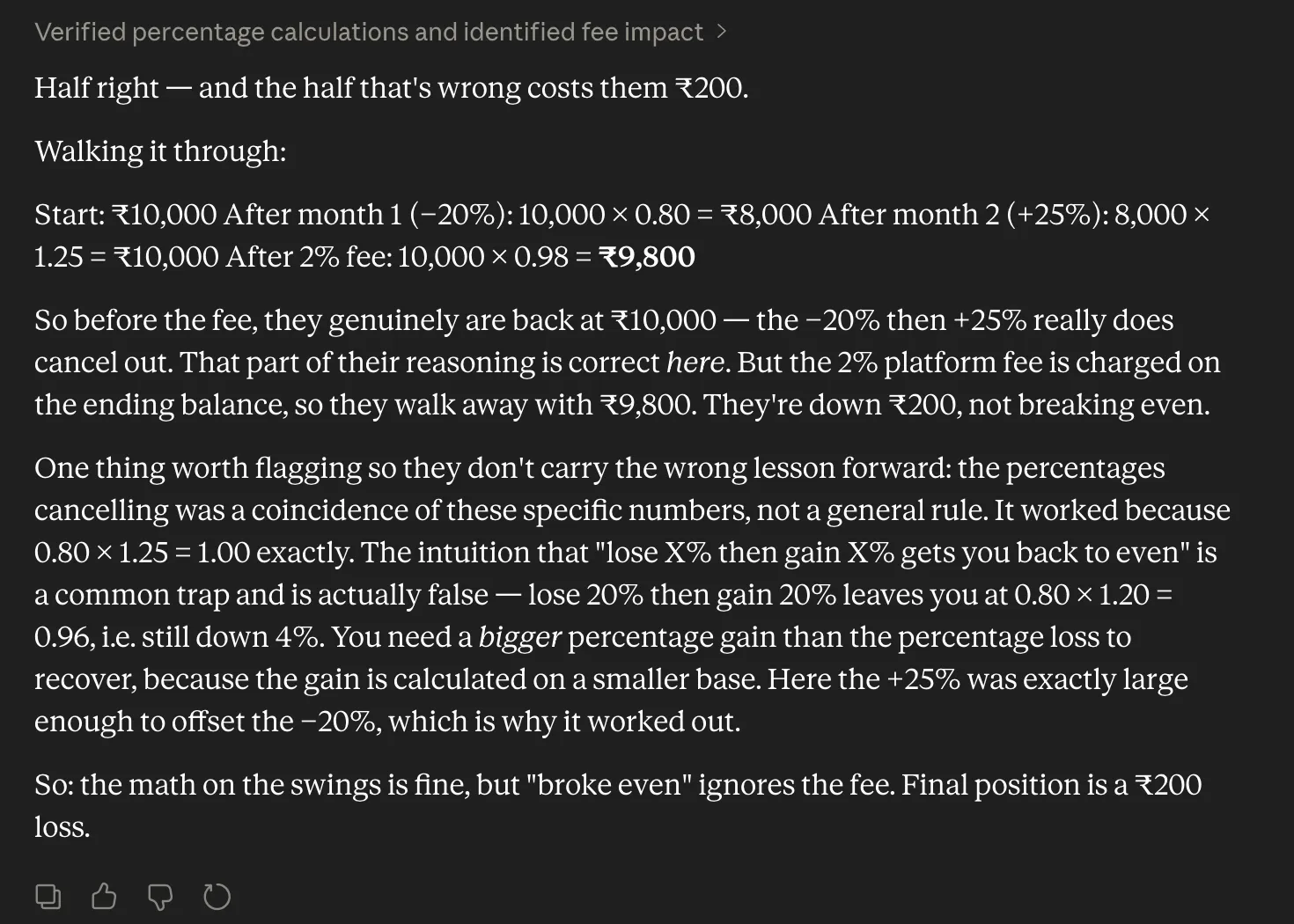
To evaluate the practical implications of these upgrades, initial hands-on testing suggests that Opus 4.8 excels in areas where logical consistency and mathematical precision are paramount. In complex reasoning scenarios—such as calculating investment returns involving fluctuating percentages and subsequent fees—the model demonstrates a superior ability to identify logical fallacies in a prompt. Where earlier models might have agreed with a user’s incorrect assumption of “breaking even,” Opus 4.8 systematically breaks down the compounding effects of losses and gains to provide a mathematically sound correction.
In coding environments, the improvement is equally visible. When presented with a multi-threaded Python script containing subtle race conditions and poor error handling, Opus 4.8 does more than just identify the bugs. It provides a comprehensive review of why the errors are occurring, suggesting specific implementations of thread-safe counters and better exception-handling protocols. This level of verification is essential for the “agentic” future Anthropic is building, where the AI must be its own first line of quality control.
Evolution of the Opus Line: 4.7 vs. 4.8
When comparing Opus 4.8 to its predecessor, the differences are less about raw power and more about refined execution. While Opus 4.7 was a breakthrough in benchmark performance, it was still prone to occasional overconfidence. Opus 4.8 is characterized by a “restrained” intelligence.
| Feature / Attribute | Claude Opus 4.7 | Claude Opus 4.8 |
|---|---|---|
| Primary Focus | Raw intelligence and benchmarks | Reliability and workflow execution |
| Coding | Strong debugging | Better verification and error detection |
| Uncertainty | Likely to guess | Surfacing uncertainty/Honesty |
| Workflows | Traditional conversational | Optimized for Dynamic Workflows |
| Effort Controls | Not available | Adjustable effort levels |
| Pricing | $5/M input, $25/M output | $5/M input, $25/M output |
For casual users, the shift may feel incremental. However, for enterprise users running millions of queries, the increase in consistency and the reduction in errors represent a significant improvement in the total cost of ownership (TCO) for AI systems.
Chronology and Context: The Broader AI Landscape
The release of Opus 4.8 comes at a time of intense competition among the “Big Three” AI labs: OpenAI, Google, and Anthropic. Earlier this year, OpenAI’s release of GPT-4o and Google’s Gemini 1.5 Pro updates focused heavily on multimodality and speed. Anthropic, which was founded by former OpenAI executives with a specific focus on “AI Safety” and “Constitutional AI,” has consistently positioned itself as the more reliable, “enterprise-grade” alternative.
This latest update follows a timeline of rapid iteration. Anthropic launched the Claude 3 family in early 2024, followed quickly by the 3.5 Sonnet and 4.7 Opus releases. Each step has seen a narrowing of the gap between the models’ ability to “chat” and their ability to “act.” The introduction of “Computer Use” capabilities in late 2024 set the stage for the agentic features seen in Opus 4.8.
Implications: From Automation to Orchestration
The industry-wide shift from conversational to operational AI carries profound implications for the global workforce and the software industry. We are moving away from a period of “simple automation”—where an AI performs a single, discrete task—and into an era of “orchestration.”
In the orchestration era, the role of the human operator shifts from “doer” to “manager.” Instead of writing code, a developer manages a fleet of subagents running on Opus 4.8 to build a system. Instead of drafting a marketing plan, a strategist oversees an AI workflow that conducts market research, generates creative assets, and analyzes budget allocations simultaneously.
Anthropic’s Opus 4.8 is not a revolutionary leap in the sense of a “new” type of intelligence. Instead, it is a sophisticated refinement of existing capabilities, polished for the demands of the modern enterprise. It reflects a realization within the AI community: the most successful models will not be those that try to sound the smartest, but those that prove to be the most dependable. By focusing on reliability, honesty, and the infrastructure of agentic work, Anthropic is positioning itself to lead the transition from AI as a novelty to AI as the backbone of global industrial and digital operations.