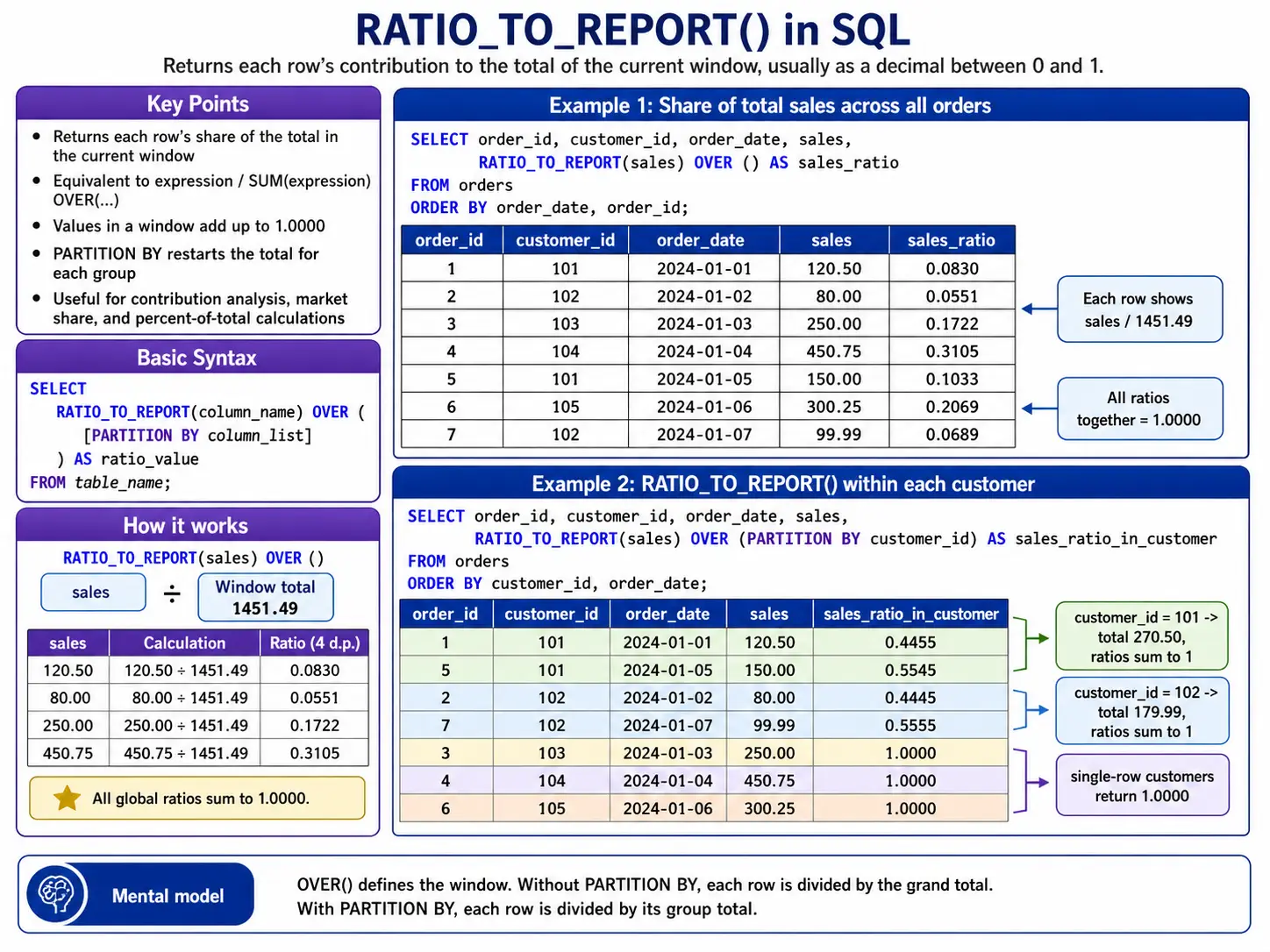
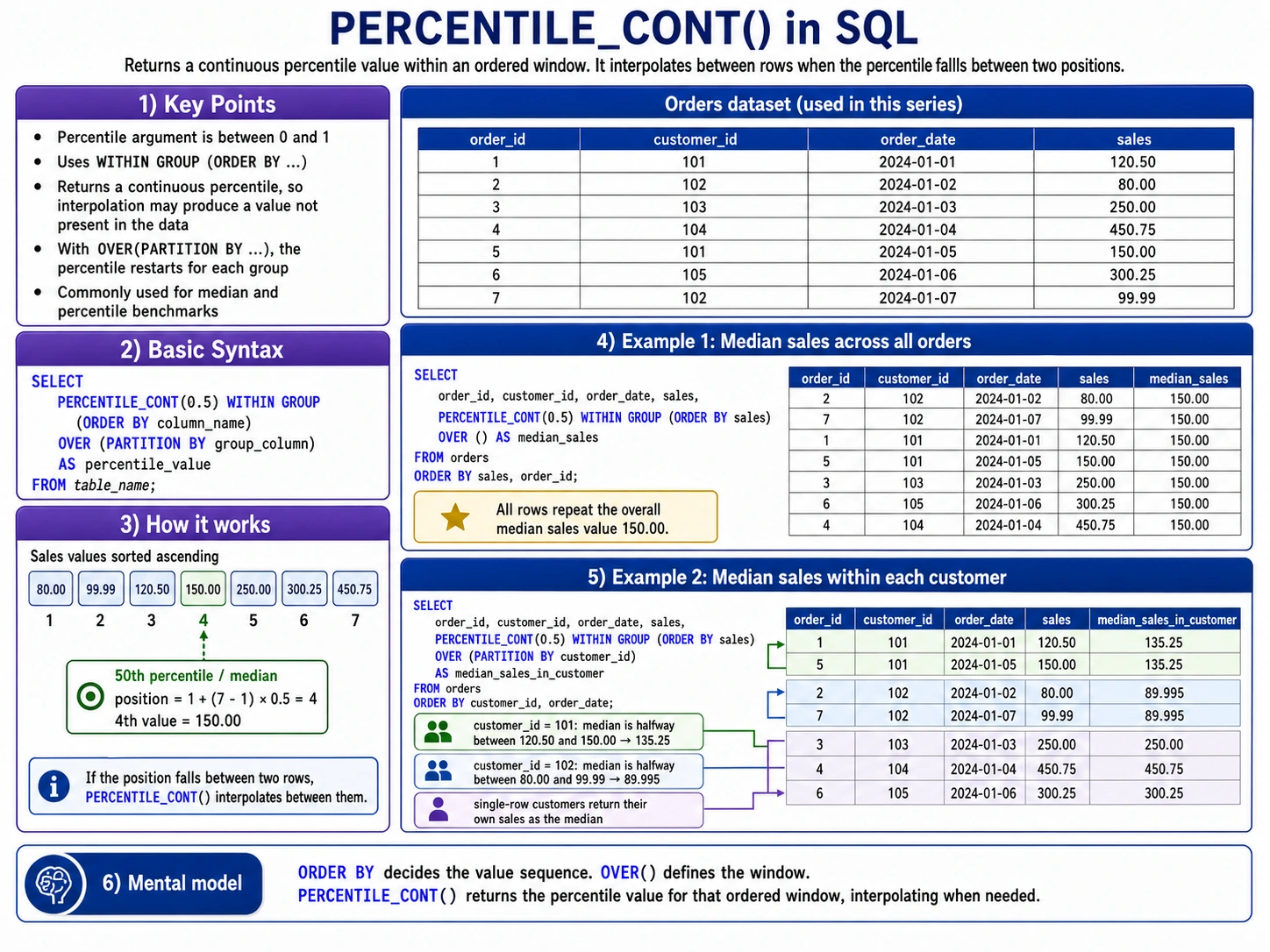
In the contemporary landscape of data science and enterprise analytics, Structured Query Language (SQL) continues to serve as the foundational bedrock for data definition, manipulation, and sophisticated analysis. While basic commands such as SELECT, FROM, and WHERE constitute the entry-level toolkit for most practitioners, the increasing complexity of modern datasets has necessitated a move toward more advanced analytical techniques. Among these, SQL window functions have emerged as a critical differentiator for data professionals, offering a powerful mechanism for performing complex calculations across sets of rows that are related to the current row, all while preserving the granularity of individual records.
The evolution of SQL from its origins at IBM in the 1970s to the current ANSI standards has been marked by a shift from simple data retrieval to high-performance analytical processing. The introduction of window functions in the SQL:2003 standard represented a significant paradigm shift, allowing for the execution of tasks that previously required cumbersome self-joins or external processing in languages like Python or R. As organizations move toward real-time decision-making, the ability to perform these operations directly within the database engine has become a matter of both computational efficiency and architectural simplicity.
The Architectural Distinction: Window Functions vs. Standard Aggregates
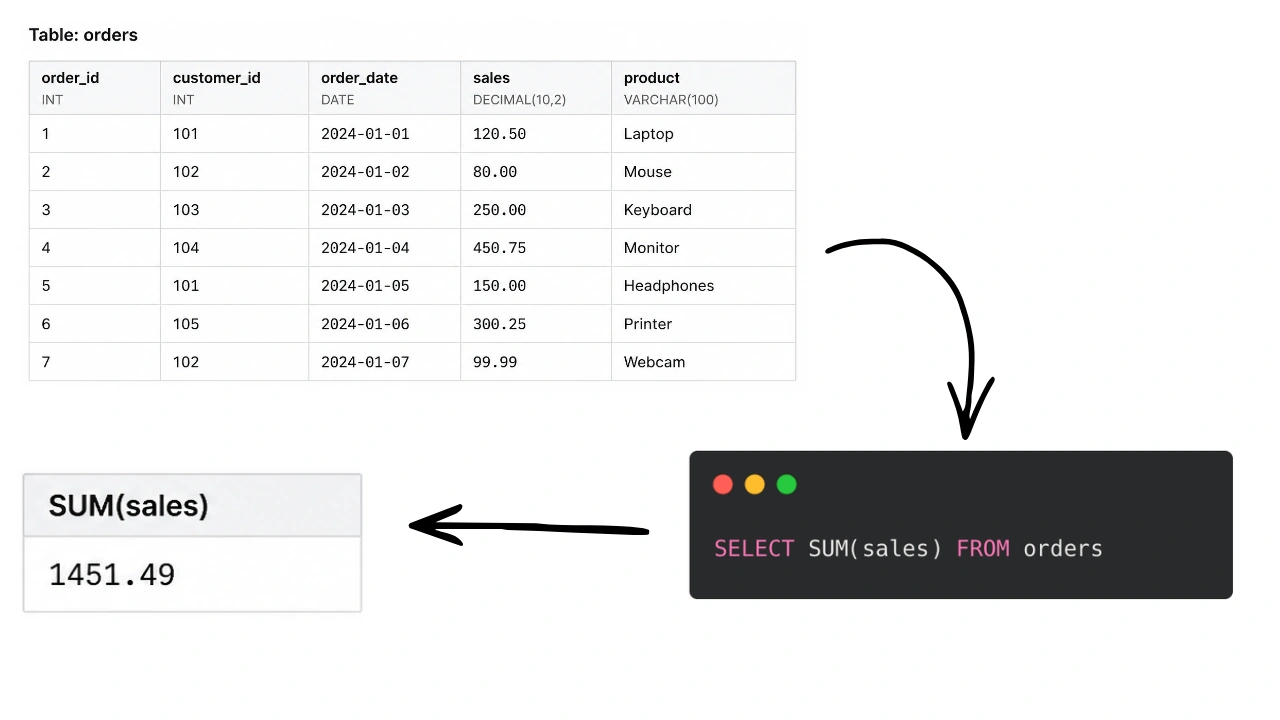
To understand the strategic value of window functions, one must first distinguish them from traditional aggregate functions. Standard aggregate functions, such as SUM(), AVG(), and COUNT(), operate on a group of rows and collapse them into a single summary row. For instance, a query calculating total sales for a fiscal quarter will return one value representing the sum of all transactions. While useful for high-level reporting, this “squishing” of data loses the context of individual transactions.

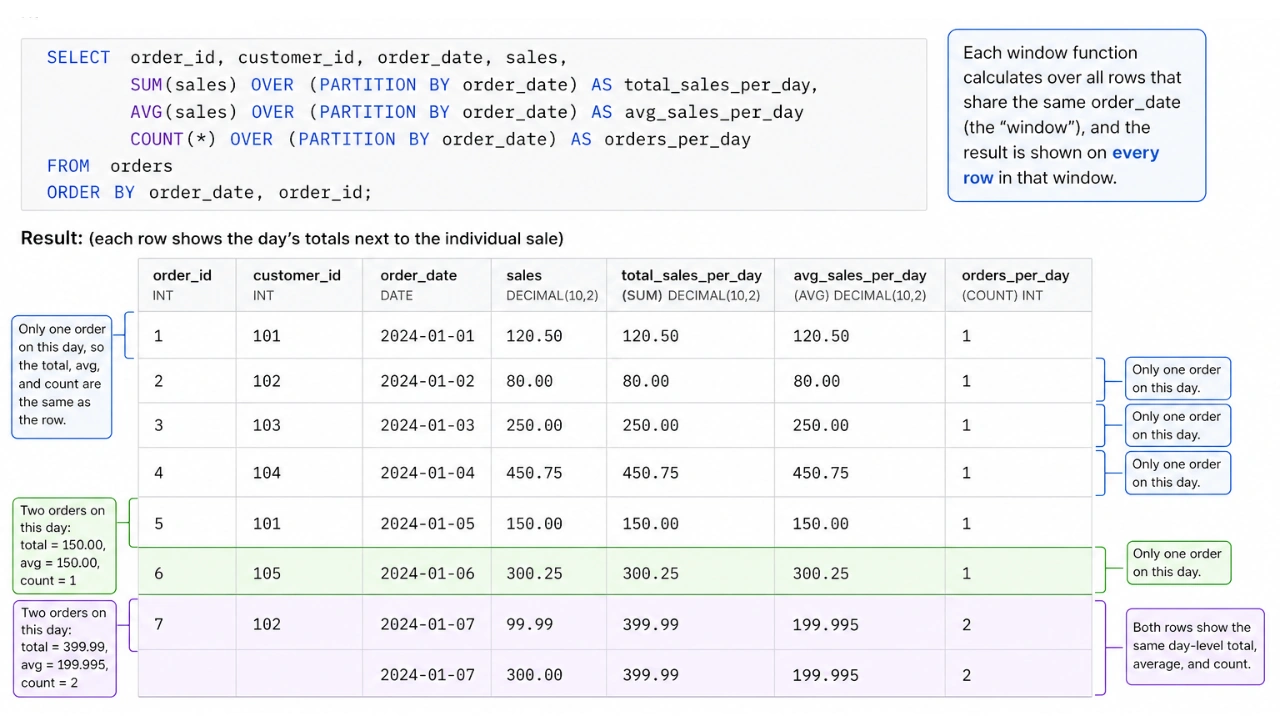
In contrast, window functions—frequently identified by the presence of the OVER() clause—perform calculations across a set of rows but return a result for every single row in the result set. This allows an analyst to view an individual sale amount alongside the daily total or a running average, providing immediate context without the need for complex subqueries. This capability is essential for time-series analysis, where the relationship between a specific data point and its neighbors is the primary focus of the investigation.
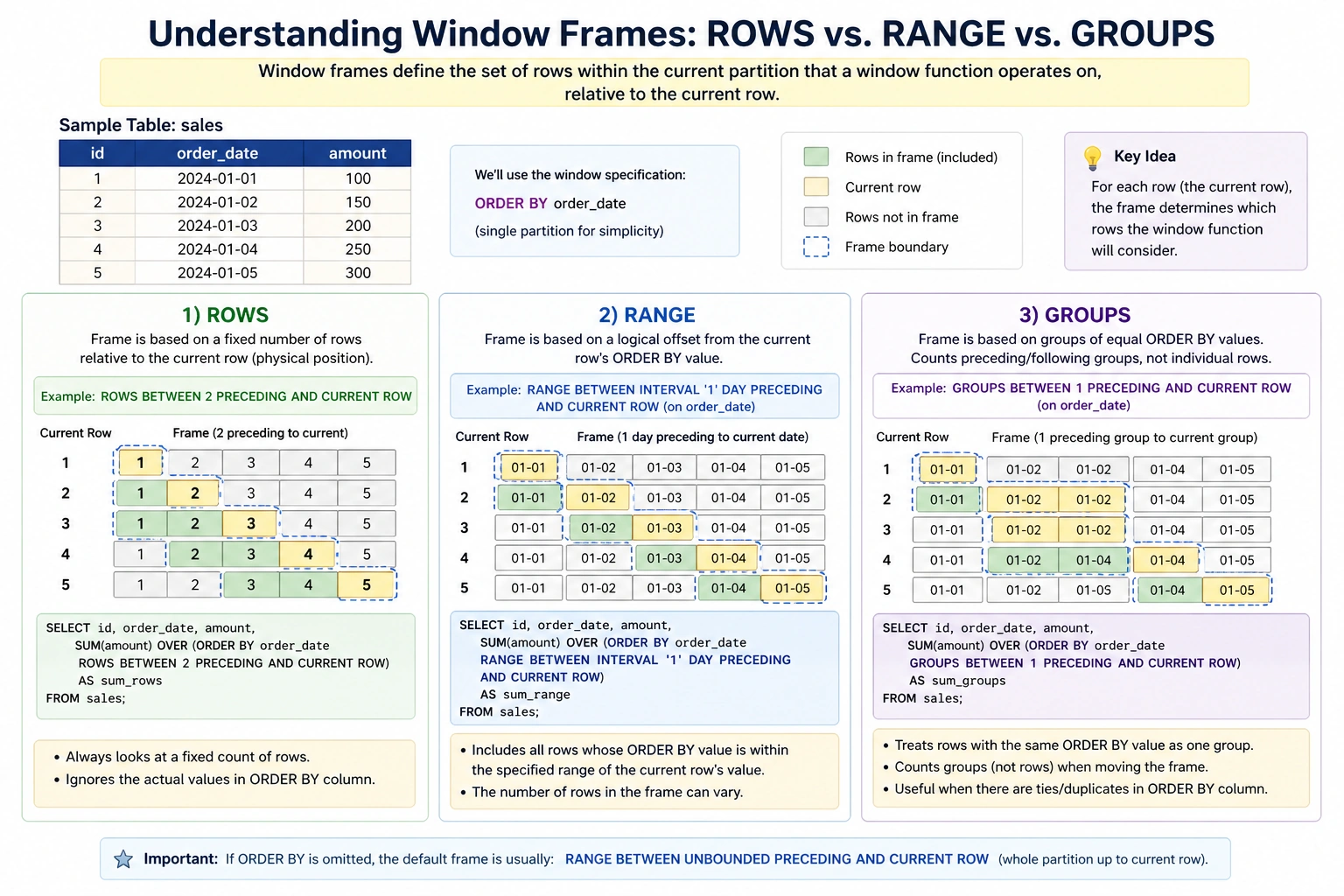
The Mechanics of the OVER() Clause and Window Framing
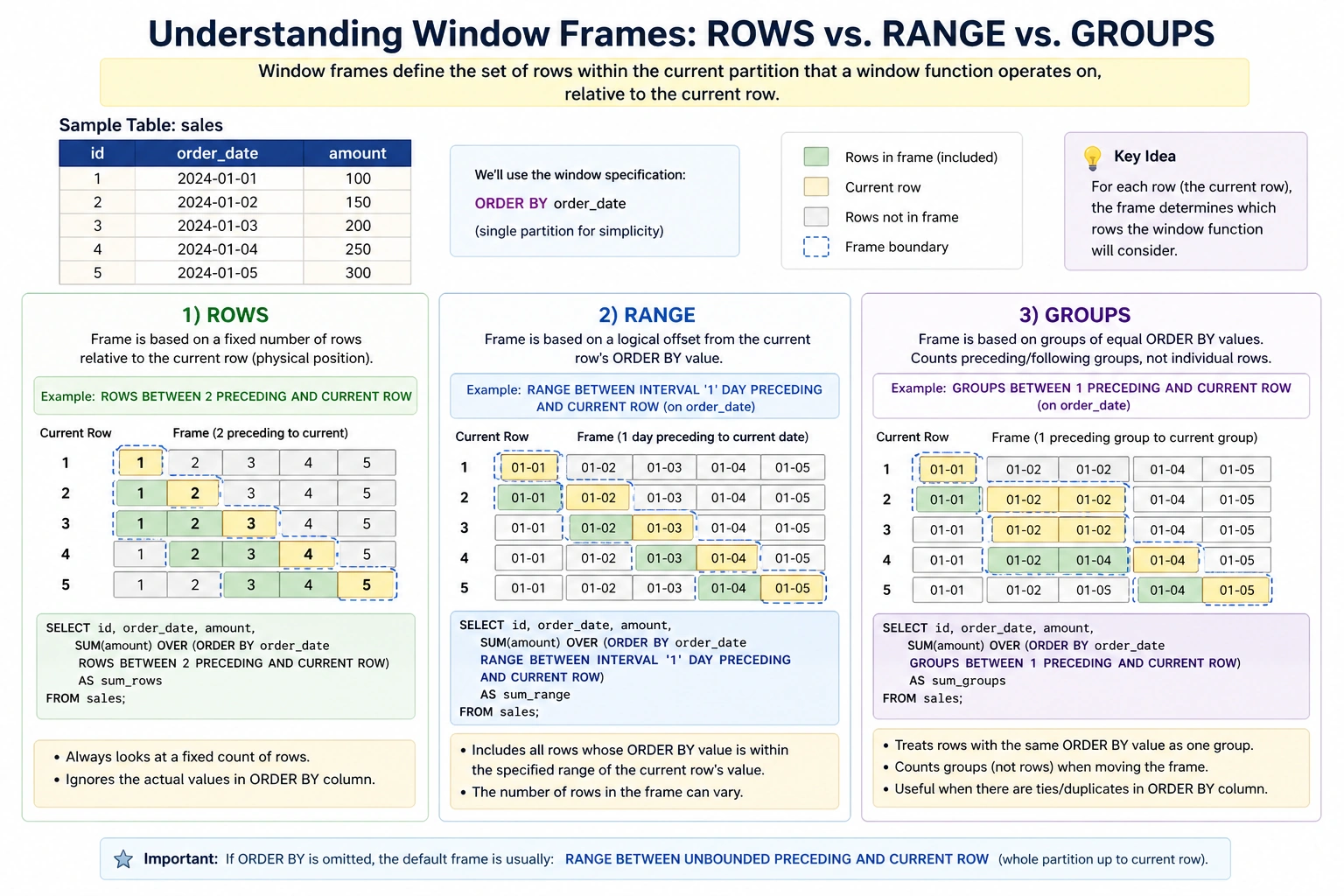
The true power of a window function lies in the OVER() clause, which defines the “window” or the specific subset of data the function should consider. This clause typically employs three primary components: PARTITION BY, ORDER BY, and window frames. The PARTITION BY subclause divides the result set into groups, such as department or region, ensuring that the calculation resets for each group. The ORDER BY subclause establishes the sequence of rows within those partitions, which is vital for calculations involving time or rank.
Beyond these, the concept of “window frames” allows for even more granular control. By using keywords such as ROWS, RANGE, or GROUPS, developers can specify a sliding window of rows relative to the current record. For example, a “moving average” might be calculated by looking at the current row and the six preceding rows. This level of precision enables the smoothing of volatile data, such as daily website traffic or stock market fluctuations, allowing underlying trends to become visible.
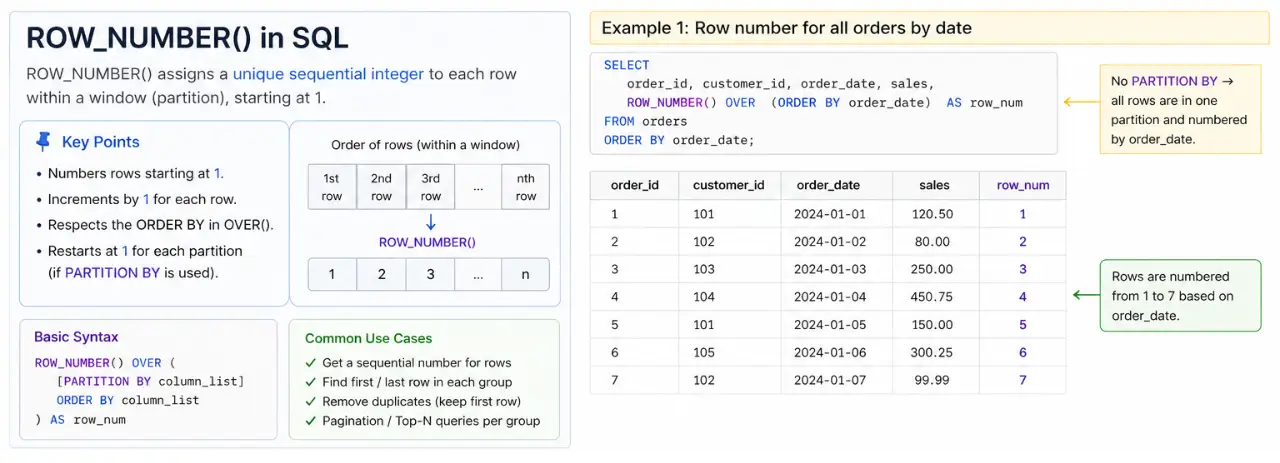
Strategic Ranking and Segmentation Functions
In the realm of business intelligence, ranking and numbering functions are indispensable for performance evaluation and customer segmentation. SQL provides several variations, each suited to specific logical requirements:
- ROW_NUMBER(): This function assigns a unique, sequential integer to rows within a partition. It is frequently used for pagination or to identify a single “best” record among duplicates.
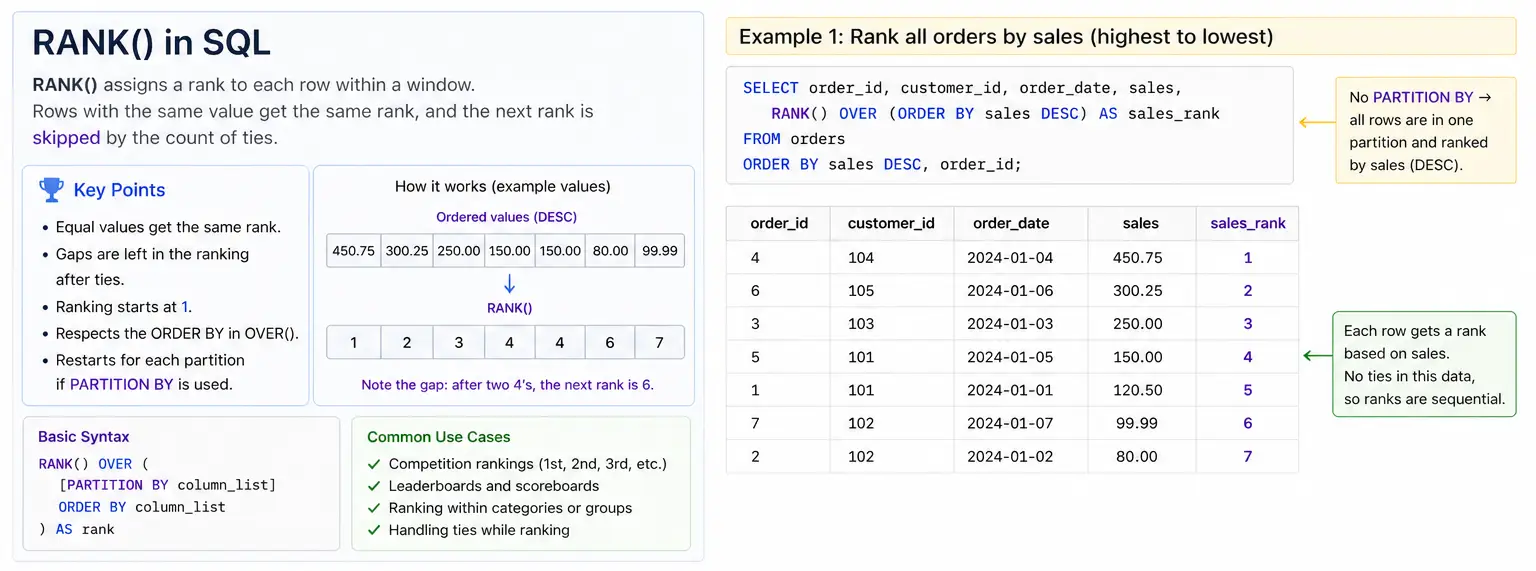
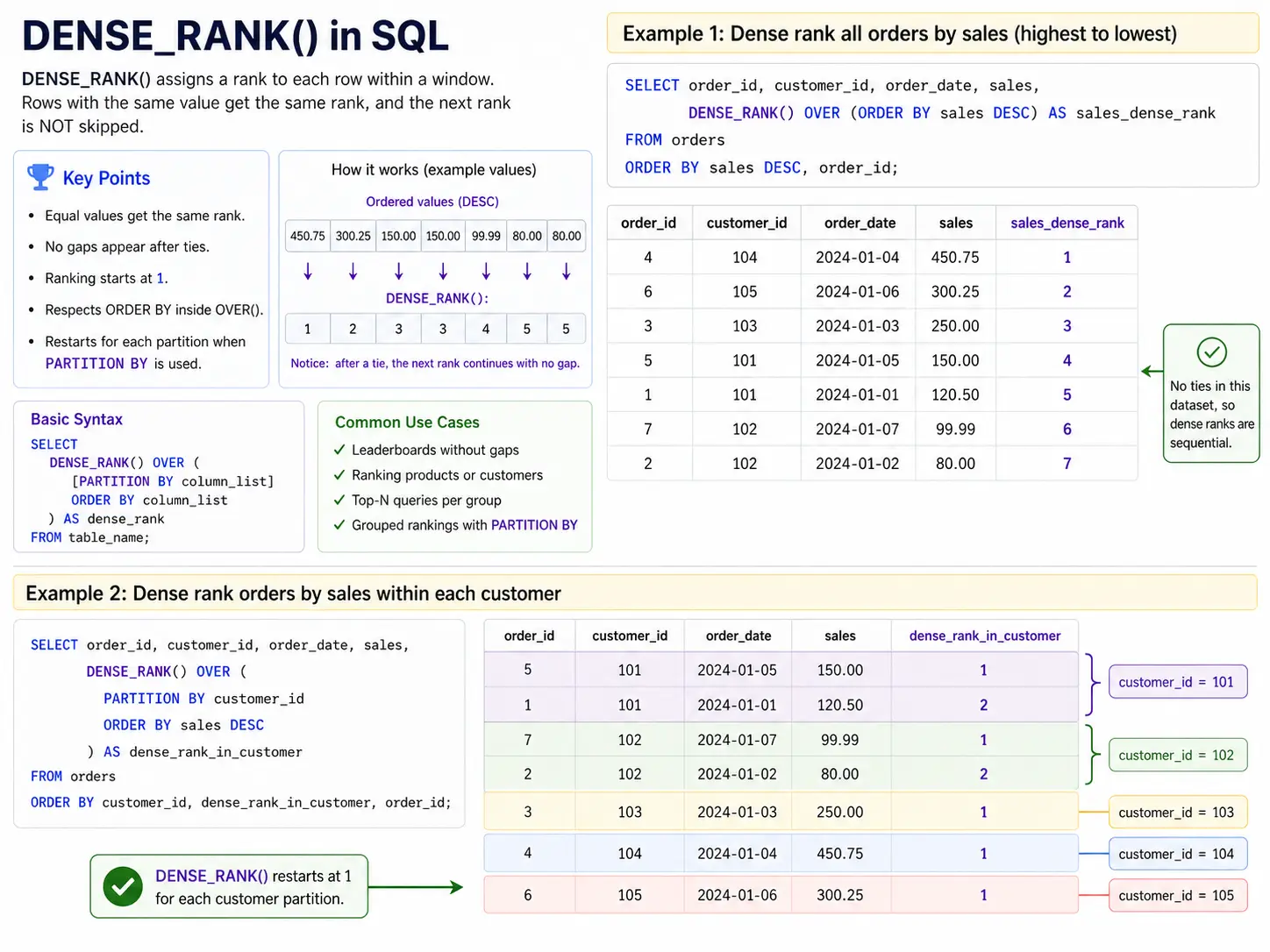
- RANK() vs. DENSE_RANK(): These functions handle ties differently. RANK() will skip subsequent numbers if a tie occurs (e.g., 1, 1, 3), whereas DENSE_RANK() maintains a continuous sequence (e.g., 1, 1, 2). This distinction is critical in competitive analysis, such as determining sales leaderboards or academic grading.
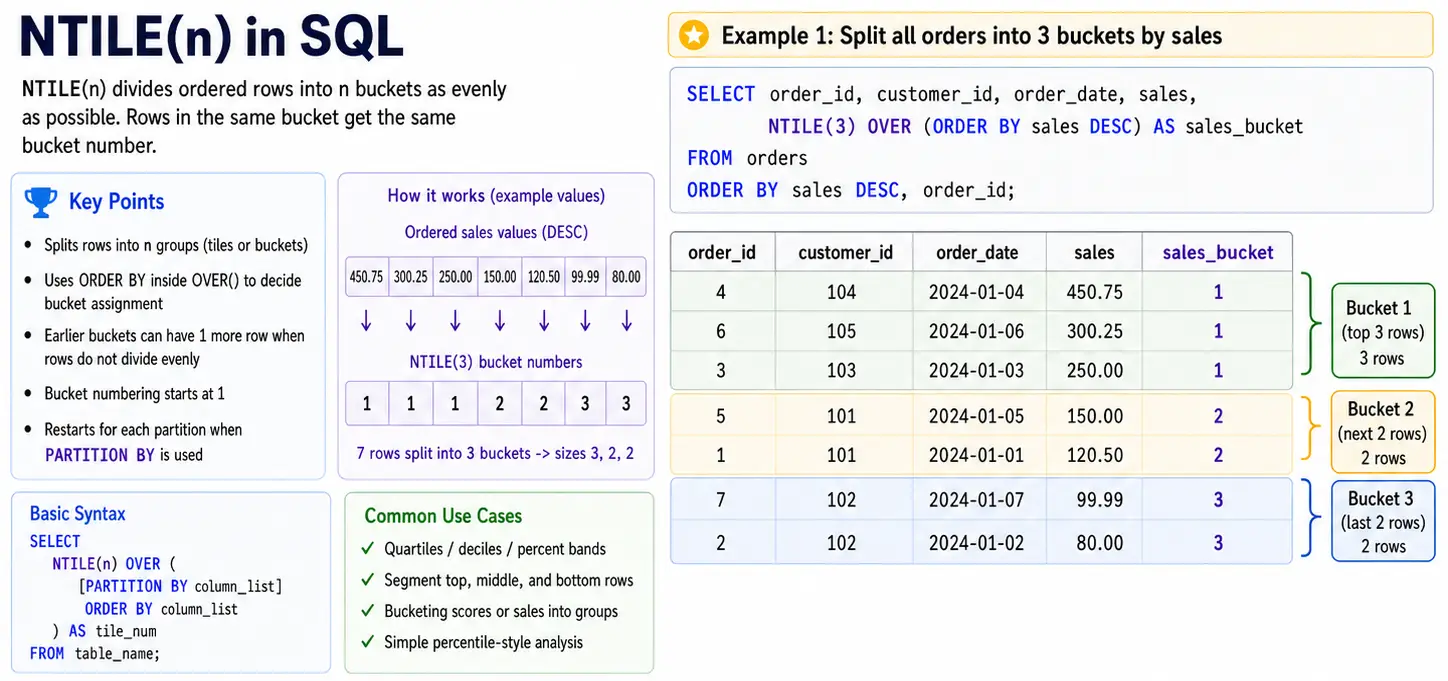
- NTILE(n): This function is a cornerstone of statistical segmentation, dividing a dataset into “n” equal groups. Analysts use NTILE(4) to create quartiles or NTILE(10) for deciles, facilitating the identification of the top 10% of customers by lifetime value or the bottom quartile of underperforming assets.
Positional Navigation and Time-Series Analysis
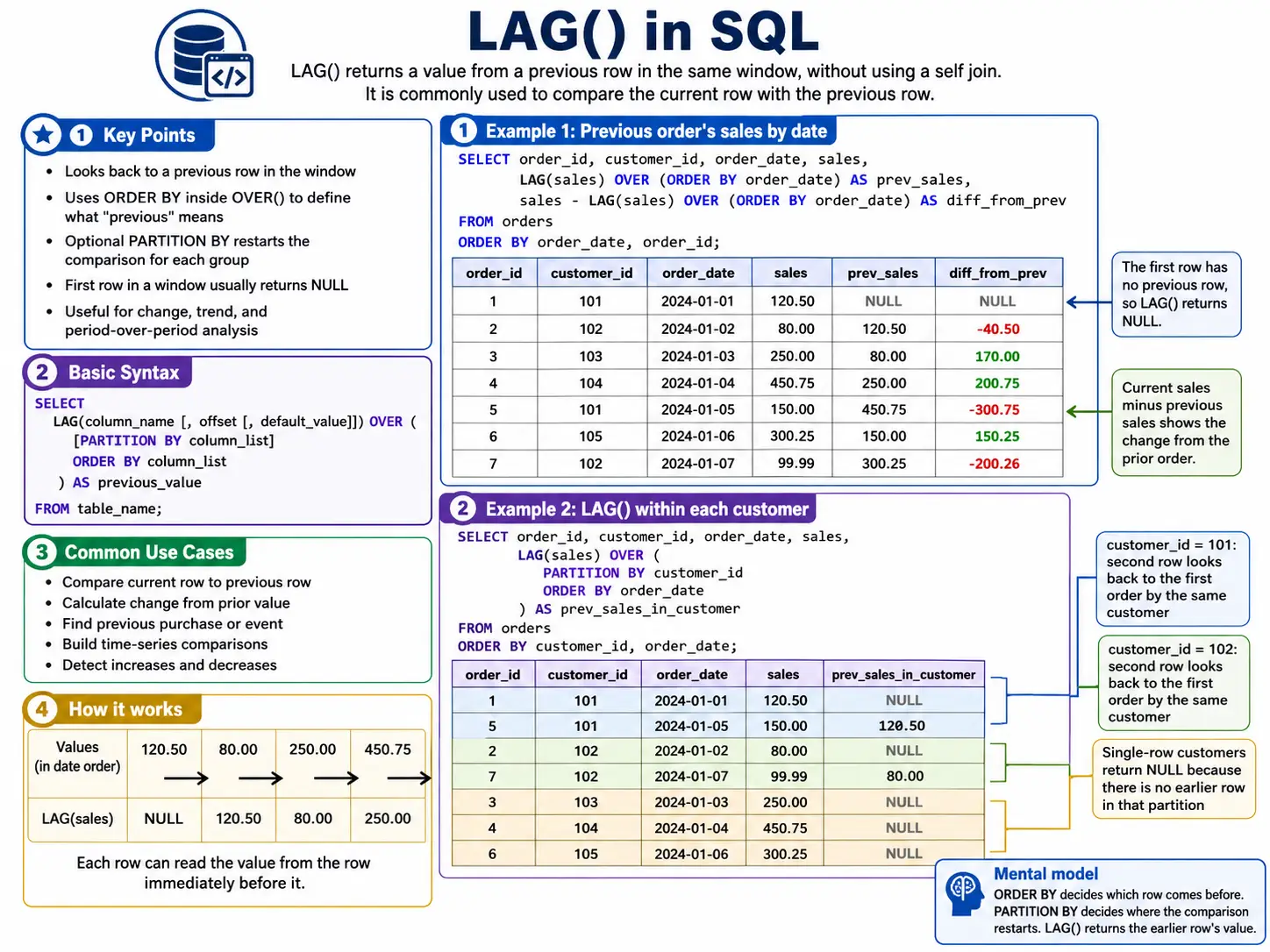
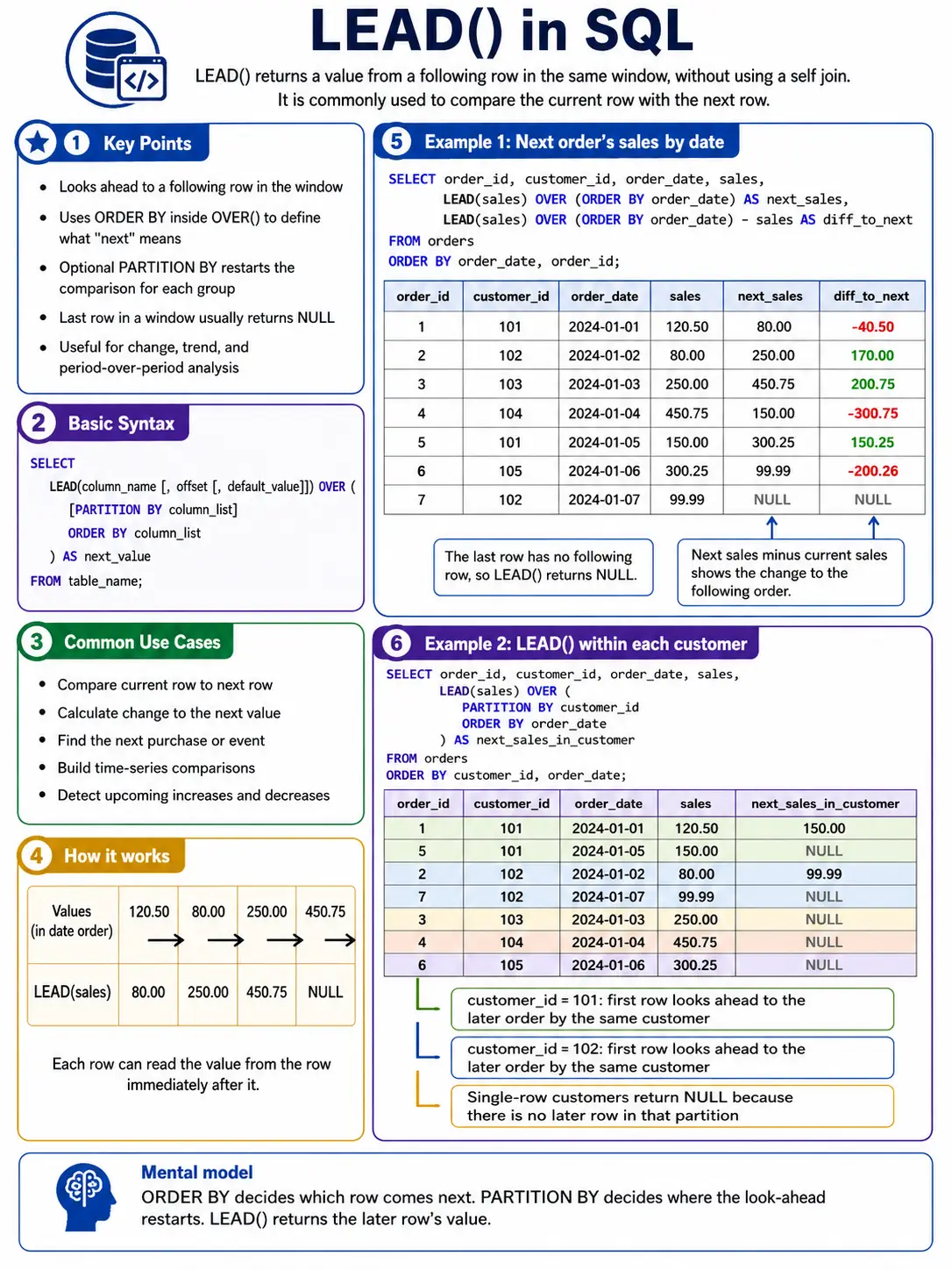
One of the most complex challenges in data analysis is comparing a current value to a previous or future state. Before window functions, this often required expensive and slow self-joins. Navigation functions like LAG() and LEAD() have revolutionized this process.
LAG() allows a query to “look back” at a previous row’s value, making it the primary tool for calculating period-over-period growth or identifying changes in user status. Conversely, LEAD() “peeks into the future,” enabling analysts to compare current performance against forecasted targets or subsequent events in a user’s journey. Further refinements such as FIRST_VALUE(), LAST_VALUE(), and NTH_VALUE() allow for the identification of baselines and endpoints within a specific partition, such as the initial purchase price in a long-term customer relationship.
Advanced Statistical and Regression Capabilities
As data science becomes more integrated into the database layer, SQL has expanded to include sophisticated statistical functions. These tools allow for in-database exploratory data analysis (EDA) and the preparation of data for machine learning models.
Functions such as STDDEV_POP() and VAR_SAMP() allow for the measurement of data volatility and spread directly within the query. More impressively, modern SQL dialects now support regression and correlation functions. CORR() provides the Pearson correlation coefficient between two variables, while REGR_SLOPE() and REGR_INTERCEPT() allow analysts to define a linear “best-fit” line across a scatter plot of data. Using REGR_R2(), practitioners can determine the reliability of these trends, identifying how much of the variance in a dependent variable is explained by the independent variable.
Platform-Specific Innovations and Scalability
While the ANSI SQL standard provides a common framework, major cloud data platforms like Snowflake, Google BigQuery, and Amazon Redshift have introduced specialized analytic functions to handle “Big Data” challenges. For instance, BigQuery offers APPROX_QUANTILES() and APPROX_COUNT_DISTINCT(), which use probabilistic algorithms to provide fast estimates on petabyte-scale datasets where exact calculations would be computationally prohibitive.

Similarly, Snowflake and BigQuery have introduced the QUALIFY clause. Historically, filtering the results of a window function required wrapping the query in a Common Table Expression (CTE) or a subquery because window functions are processed after the WHERE clause. The QUALIFY clause allows for direct filtering of window results, significantly cleaning up code and improving readability for complex engineering pipelines.

The Logical Order of Execution: A Critical Insight
To utilize these functions effectively, one must understand the logical order of SQL execution. SQL queries are not processed in the order they are written. The typical sequence is:

- FROM (and JOINS)
- WHERE
- GROUP BY
- HAVING
- WINDOW FUNCTIONS
- SELECT
- DISTINCT
- ORDER BY
- LIMIT / OFFSET
Because window functions are executed in step 5, they cannot be used within a WHERE clause to filter rows. This execution hierarchy is the reason why analysts must often use subqueries or the aforementioned QUALIFY clause to isolate specific ranked results. Understanding this “under-the-hood” logic is essential for debugging performance issues and ensuring the accuracy of complex reports.
Broader Impact and Industry Implications
The mastery of advanced window functions represents a significant shift in the division of labor within data teams. By performing complex logic at the database level, data engineers can deliver “cleaner” and more enriched datasets to downstream consumers. This reduces the computational burden on visualization tools like Tableau or PowerBI, which often struggle with high-cardinality calculations.
Furthermore, in the era of Generative AI and Large Language Models (LLMs), the demand for precise data structuring has never been higher. LLMs rely on well-organized context to provide accurate insights, and SQL window functions provide the most efficient path to creating that context. As organizations continue to move toward “Data Mesh” and “Data Contract” architectures, the ability to write robust, efficient, and readable SQL remains the most sought-after skill in the data economy.

Conclusion
SQL window functions are no longer an “optional” advanced skill; they are a fundamental requirement for modern data science and analytical engineering. From basic ranking to complex linear regression and platform-specific optimizations, these functions allow for a level of analytical depth that was previously unattainable within a single query. By bridging the gap between simple data retrieval and complex statistical modeling, window functions empower practitioners to uncover deeper insights, optimize computational resources, and drive more informed business strategies in an increasingly data-driven world. For the data professional looking to stand out in a crowded field, the mastery of these 40+ functions and the underlying logic of the OVER() clause is the definitive path to technical excellence.