The narrative of digital transformation often begins with high-stakes ambition and ends in the quiet stagnation of bureaucratic delay, a phenomenon recently highlighted by industry experts as the “Big Test Trap.” Consider the case of a typical enterprise product team, led by a manager we will call Alex. After months of internal lobbying, Alex finally secured executive buy-in for an experimentation program. The mandate from leadership was clear: the first test had to be significant enough to prove the entire department’s value. Consequently, the team bypassed minor optimizations in favor of a massive, structural overhaul of the checkout flow. Three months into the project, the experiment was still trapped in design reviews; six months later, it remained buried in the development backlog. By the time a year had passed, the initial momentum had evaporated, the budget was reassessed, and the experimentation program was quietly shuttered before a single user had even seen a variation.
This cautionary tale is not an outlier but a recurring pattern in the world of Conversion Rate Optimization (CRO). Lucia van den Brink, the founder of The Initial and a prominent voice in the experimentation space, has observed this cycle repeat across diverse organizations. Speaking on the VWO Podcast, van den Brink detailed how the pursuit of “transformative” changes often serves as the primary catalyst for program failure. To combat this, she proposes a strategic shift toward sustainable experimentation—a framework that prioritizes habit-building and incremental learning over the high-risk “all-or-nothing” swings that frequently paralyze modern marketing and product teams.
The Anatomy of the Big Test Trap
The Big Test Trap is rooted in a fundamental misunderstanding of how digital growth occurs. When organizations commit to experimentation, there is an almost universal instinct to start with a massive initiative. This occurs for several psychological and structural reasons. First, large-scale projects naturally attract the attention of senior leadership, who are often looking for “silver bullet” solutions to complex revenue problems. Second, there is a pervasive, though often fallacious, belief that the impact of an experiment is directly proportional to the size of the change.
In practice, this logic frequently collapses. Large-scale tests require extensive cross-departmental coordination, involving legal, brand, design, and engineering teams. This complexity leads to “development purgatory,” where the time-to-market for a single test stretches into quarters rather than weeks. Furthermore, when a massive redesign is eventually launched, the “noise” of so many simultaneous changes makes it nearly impossible to isolate which specific variable drove the result. If the test fails, the team has wasted months of resources with no actionable data; if it succeeds, they still do not truly understand why.
Lucia van den Brink notes that this approach neglects the most critical element of a successful program: the habit of testing. “Recently, I spoke to a product owner whose first test was a fraud detection system,” van den Brink shared. “In another case, a client started with a full redesign of their homepage. These are massive undertakings that delay the learning phase, which is exactly what you need to build a sustainable culture.”

A Chronology of Experimentation Maturity
To understand the impact of the Big Test Trap, it is helpful to examine the typical timeline of an experimentation program that falls into this snare versus one that follows a sustainable framework.
Month 1-3: The Ambition Phase
In the “Trap” model, the team spends the first quarter in high-level meetings, selecting a “flagship” experiment. In the sustainable model, the team focuses on “plumbing”—setting up tracking, establishing a baseline, and launching three to five “micro-tests” (such as headline changes or CTA placements) to test the pipes.
Month 4-6: The Execution Gap
By the second quarter, the “Trap” team is usually embroiled in design disputes or technical constraints regarding their massive project. Morale begins to dip as stakeholders ask for results that do not yet exist. Conversely, the sustainable team has already completed ten small tests. Even if eight were “losers,” they have gained ten data points about user behavior and have refined their deployment workflow.
Month 7-12: The Divergence
In the final half of the year, the “Trap” program often loses its funding or executive championship due to a lack of ROI. The sustainable program, having accumulated a series of “small wins,” now has the political capital and the data-backed confidence to attempt a larger strategic experiment.
The 4-Step Framework for Sustainable Growth
To avoid the pitfalls of over-ambition, van den Brink outlines a four-step framework designed to balance the need for results with the necessity of operational agility.
Step 1: Recognize the Psychological Bias
The first step is cultural. Teams must acknowledge that the urge to “go big” is often a manifestation of loss aversion or a desire for professional validation rather than a sound data strategy. By recognizing that large tests are inherently slower and riskier, teams can reset stakeholder expectations. The goal of the first six months should not be “revenue transformation” but “velocity and insight generation.”

Step 2: Prioritize High-Impact, Low-Complexity Tests
Sustainable programs thrive on the “low-hanging fruit” that larger organizations often overlook. Modest changes—such as clarifying value propositions, reducing form fields, or adjusting visual hierarchy—often produce results that rival major overhauls. These tests are less risky because they do not fundamentally alter the core user experience, allowing for rapid iteration.
For example, a B2B SaaS company might spend three months building the infrastructure for a new onboarding flow. Alternatively, they could spend one week testing the messaging on their current “Get Started” page. The latter provides immediate feedback on user intent, which can then inform the design of the larger onboarding project.
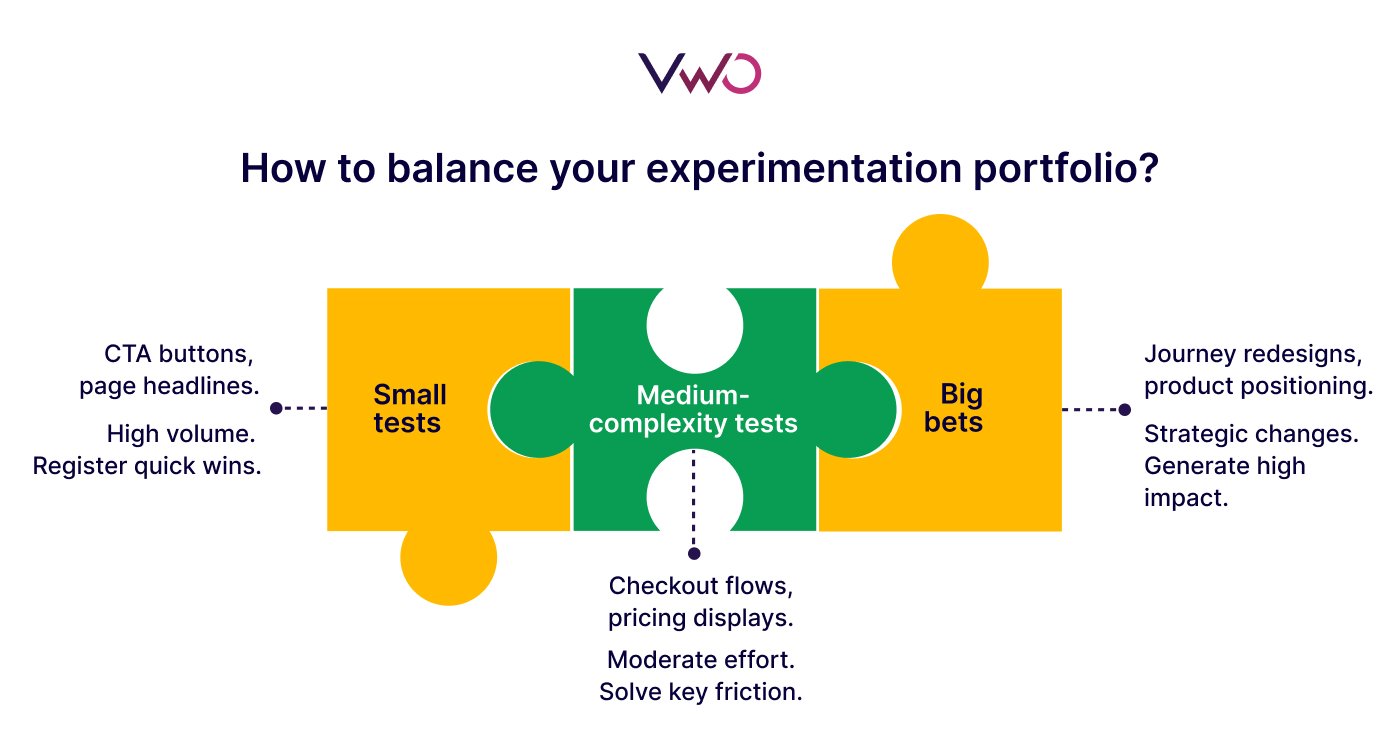
Step 3: Strategic Portfolio Balancing
Once a team has established a rhythm, they must manage their experiments like a financial portfolio. A healthy experimentation program should not consist solely of small tests, nor should it be dominated by “moonshots.” Van den Brink suggests a balanced approach:
- 70% Incremental Tests: Low-effort, high-velocity experiments focused on optimization.
- 20% Iterative Tests: Medium-complexity experiments that build on previous learnings.
- 10% Disruptive Tests: High-risk, high-reward strategic shifts (e.g., pricing model changes or new product features).
This ensures that the program remains productive even if the “big swings” do not pan out.
Step 4: Use Big Tests for Validation, Not Exploration
One of the most profound shifts in the van den Brink framework is the role of the large-scale experiment. In failing programs, big tests are used to “explore” new ideas. In successful programs, big tests are used to “validate” hypotheses that have already been supported by smaller data points.
If a series of small copy tests indicate that users respond better to “benefit-driven” messaging than “feature-driven” messaging, a subsequent full-page redesign should be built entirely around benefit-driven principles. In this scenario, the big test isn’t a shot in the dark; it is the final confirmation of a proven behavioral trend.
Industry Data and the Cost of Inaction
The shift toward this incremental, data-driven approach is supported by broader industry trends. According to data from various CRO platforms, including VWO, the average win rate for A/B tests across all industries hovers between 12% and 25%. This means that roughly three out of four experiments will not result in a statistically significant improvement.
When an organization puts all its resources into one “Big Test” per year, they are effectively gambling their entire program on a 25% chance of success. However, a team that runs 50 small tests per year—even with the same 25% win rate—will secure 12 to 13 winning variations. The cumulative effect of these small wins, often referred to as “compounding gains,” frequently outperforms the single “home run” that many executives chase.
Furthermore, the “cost of delay” is a significant factor. In software engineering and product management, the cost of delay refers to the lost opportunity of not having a feature or optimization live in the market. A test that takes six months to launch doesn’t just cost the salary of the developers; it costs six months of potential revenue uplift that a faster, smaller test could have captured in week two.
Broader Implications for Corporate Culture
Beyond the metrics of conversion rates and revenue, the “Big Test Trap” has a profound impact on organizational culture. When experimentation is treated as a rare, high-stakes event, it creates a culture of fear. Team members become hesitant to propose ideas because the “cost of failure” is perceived as being too high.
Conversely, when experimentation is frequent and low-friction, failure is de-stigmatized. It becomes a “learning” rather than a “loss.” This cultural shift is essential for long-term agility. As van den Brink emphasizes, “I’m always an advocate for starting small. Get evidence for the case of experimentation, and why it’s good… slowly get more people on board, and get evidence for the case of working data-driven.”
In an era where consumer behavior shifts rapidly and digital landscapes are increasingly competitive, the ability to learn quickly is a greater competitive advantage than the ability to build grandly. Organizations that escape the Big Test Trap do so by realizing that the “hard part” isn’t choosing the biggest thing to test—it’s having the discipline to start small and the consistency to keep going. Through balanced portfolios and a focus on velocity, companies can transform experimentation from a series of stalled projects into a self-sustaining engine of growth.