The field of Natural Language Processing (NLP) has undergone a seismic shift over the last decade, transitioning from statistical models based on word frequency to sophisticated neural architectures capable of understanding context and nuance. At the forefront of this evolution in document organization is BERTopic, a modular topic modeling framework that leverages transformer embeddings and class-based TF-IDF to uncover latent themes within massive datasets. Unlike its predecessor, Latent Dirichlet Allocation (LDA), which treats documents as "bags of words," BERTopic maintains the semantic integrity of the text, allowing researchers and data scientists to extract topics that are not only statistically significant but also human-interpretable.
The Shift from Statistical to Semantic Topic Modeling
For nearly two decades, Latent Dirichlet Allocation (LDA) served as the industry standard for topic modeling. Developed by David Blei, Andrew Ng, and Michael Jordan in 2003, LDA operates on the premise that documents are a mixture of topics and topics are a mixture of words. However, LDA possesses inherent limitations that have become more pronounced in the era of "Big Data." It struggles with short texts, requires the user to pre-define the number of topics (the ‘k’ parameter), and completely ignores the order and context of words.

The emergence of Bidirectional Encoder Representations from Transformers (BERT) in 2018 by Google researchers revolutionized how machines process language. By training on massive corpora using masked language modeling, BERT learned to understand that the word "bank" in "river bank" differs fundamentally from "bank" in "investment bank." BERTopic, introduced by Maarten Grootendorst in 2020, represents the practical application of these transformer capabilities to the problem of topic discovery. By utilizing these embeddings, BERTopic can group documents based on their underlying meaning rather than the mere repetition of specific keywords.
The Modular Architecture: A Five-Step Pipeline
The strength of BERTopic lies in its modularity. It is not a single monolithic algorithm but rather a pipeline of independent components that can be swapped or tuned depending on the specific requirements of the dataset.
1. Document Embeddings
The process begins by converting raw text into dense numerical vectors. While BERTopic is framework-agnostic, it typically utilizes Sentence-BERT (SBERT). These models are fine-tuned to ensure that semantically similar sentences are mapped to close points in a high-dimensional vector space. This step ensures that the model "understands" the relationship between a document discussing "astrophysics" and one discussing "galactic clusters," even if they share few identical words.

2. Dimensionality Reduction (UMAP)
High-dimensional embeddings, often exceeding 768 dimensions, suffer from the "curse of dimensionality," making clustering computationally expensive and geometrically difficult. BERTopic employs Uniform Manifold Approximation and Projection (UMAP) to compress these embeddings into a lower-dimensional space (typically 2 to 10 dimensions). Unlike older techniques like Principal Component Analysis (PCA), UMAP excels at preserving both the local and global structure of the data, ensuring that related documents remain grouped together after reduction.
3. Density-Based Clustering (HDBSCAN)
Once the data is projected into a lower-dimensional space, Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) is used to identify clusters. HDBSCAN is particularly effective because it does not require a pre-specified number of clusters. Instead, it identifies dense regions of documents as topics and labels sparse data points as "noise" (Topic -1). This allows the model to naturally discover the number of themes present in a dataset, providing a more objective reflection of the content.
4. Tokenization and Bag-of-Words
After clusters are formed, all documents within a single cluster are concatenated into a single "meta-document." This allows the model to treat each cluster as a distinct class, preparing the data for the final step of topic representation.
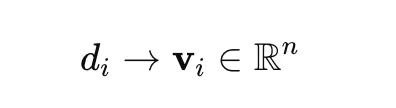
5. Class-based TF-IDF (c-TF-IDF)
The final and perhaps most innovative step is the c-TF-IDF calculation. Traditional TF-IDF evaluates the importance of a word within a single document. c-TF-IDF, however, evaluates the importance of a word within a cluster (class). By comparing the frequency of a word in one cluster against its frequency across all clusters, the model identifies the most descriptive terms for that specific topic. This results in a list of keywords that accurately summarize the theme of each cluster.
Technical Chronology and Development
The development of BERTopic follows a clear timeline of advancements in open-source machine learning. Following the 2018 release of BERT, the community sought ways to make these models more accessible for document-level tasks. In 2019, the release of the sentence-transformers library provided the necessary infrastructure for efficient document embeddings.
By 2020, Grootendorst integrated these embeddings with UMAP and HDBSCAN, creating the first iteration of BERTopic. Since then, the framework has been updated to support multimodal topic modeling (images and text), dynamic topic modeling (tracking themes over time), and hierarchical topic modeling. As of 2024, BERTopic has become one of the most downloaded NLP libraries on GitHub and PyPI, used by organizations ranging from academic institutions to Fortune 500 companies for large-scale text analysis.
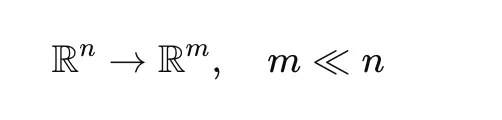
Hands-On Implementation: A Step-by-Step Walkthrough
To understand the practical utility of BERTopic, one must look at its implementation. Even with a minimal dataset, the framework’s ability to differentiate between distinct semantic fields is evident.
Step 1: Environment Setup and Data Preparation
Implementation begins with importing the necessary modules. For small datasets, specific configurations are required to ensure the underlying algorithms (UMAP and HDBSCAN) function correctly without spectral errors.
import re
import umap
import hdbscan
from bertopic import BERTopic
# Sample documents representing diverse themes
docs = [
"NASA launched a satellite to explore the lunar surface.",
"Philosophy and religion are deeply related in ancient texts.",
"Space exploration is growing with private sector investment.",
"Existentialism is a key branch of modern philosophy."
]Step 2: Preprocessing
While transformers handle raw text well, basic normalization—such as lowercasing and removing excessive whitespace—remains a best practice to ensure token consistency.
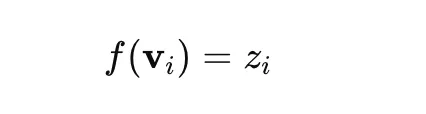
def preprocess(text):
text = text.lower()
text = re.sub(r"s+", " ", text)
return text.strip()
docs = [preprocess(doc) for doc in docs]Step 3: Component Configuration
For specialized datasets, the UMAP and HDBSCAN models are configured manually. In this instance, we set n_neighbors=2 because of the extremely small sample size, and we use min_cluster_size=2 to force the algorithm to look for even the smallest thematic groupings.
umap_model = umap.UMAP(
n_neighbors=2,
n_components=2,
min_dist=0.0,
metric="cosine",
random_state=42,
init="random"
)
hdbscan_model = hdbscan.HDBSCAN(
min_cluster_size=2,
metric="euclidean",
cluster_selection_method="eom",
prediction_data=True
)Step 4: Model Training and Inference
The BERTopic object is initialized with these custom components. The fit_transform method then executes the entire pipeline, returning the assigned topic for each document and the probability of those assignments.
topic_model = BERTopic(
umap_model=umap_model,
hdbscan_model=hdbscan_model,
calculate_probabilities=True,
verbose=True
)
topics, probs = topic_model.fit_transform(docs)Step 5: Analysis of Results
The output allows the user to see which words the model deemed most representative. For the sample data provided, the model would likely separate the documents into two topics: "Space/NASA" and "Philosophy/Religion."
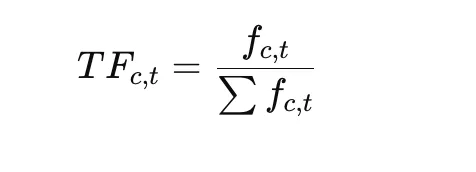
Industry Impact and Performance Metrics
The adoption of BERTopic has had a measurable impact on how industries handle unstructured data. In the realm of customer experience, companies use BERTopic to analyze thousands of daily support tickets. By identifying emerging "topics" in real-time, firms can detect product defects or service outages hours before they would be caught by manual review.
In academic research, BERTopic is used for "Science of Science" studies, where researchers analyze decades of publication abstracts to map the evolution of scientific fields. Unlike LDA, which often produces "noisy" topics with overlapping keywords, BERTopic’s use of c-TF-IDF results in higher "Topic Coherence" scores—a standard metric used to evaluate how well the keywords in a topic relate to one another.
However, the framework is not without its costs. Generating transformer embeddings is computationally intensive. Processing a dataset of one million documents can take several hours on a standard CPU, whereas LDA might complete the task in minutes. Consequently, the industry has seen a rise in the use of GPU-accelerated embedding services and cloud-based NLP pipelines to accommodate BERTopic’s requirements.
Future Implications and Conclusion
The future of topic modeling appears to be trending toward even deeper integration with Large Language Models (LLMs). Recent updates to the BERTopic ecosystem allow users to pipe the c-TF-IDF keywords into models like GPT-4 or Llama 3 to generate natural language labels for each topic. Instead of seeing a topic represented as "space, nasa, launch," the model can now provide a coherent label like "Recent Developments in Aerospace Engineering."
As organizations continue to generate vast amounts of text data, the ability to organize and understand that data at scale becomes a competitive necessity. BERTopic represents a significant leap forward, bridging the gap between raw machine learning power and human-readable insights. By combining the contextual awareness of transformers with the statistical rigor of c-TF-IDF, it provides a robust, flexible, and highly interpretable solution for the modern data landscape.
In conclusion, while traditional methods like LDA paved the way, the modularity and semantic depth of BERTopic make it the definitive choice for contemporary NLP tasks. As embedding models become more efficient and dimensionality reduction techniques more refined, BERTopic will likely remain the standard-bearer for topic discovery in the years to come.