As artificial intelligence transitions from a specialized academic discipline to a cornerstone of global economic infrastructure, the vocabulary surrounding the technology has become increasingly pervasive yet remains frequently misunderstood. While tools such as ChatGPT, Claude, and Gemini have achieved record-breaking adoption rates, a significant gap persists between the functional use of these systems and a fundamental understanding of their underlying mechanics. To bridge this divide, industry analysts and computer scientists have identified ten core concepts that represent the architectural and operational foundation of modern AI. Understanding these pillars—ranging from the probabilistic nature of Large Language Models to the burgeoning capabilities of autonomous agents—is no longer a requirement solely for developers, but a necessity for professionals across all sectors navigating the Fourth Industrial Revolution.
The Evolution of Machine Intelligence: A Brief Chronology
The current "AI Summer" did not emerge in a vacuum but is the result of decades of incremental breakthroughs in neural networks and computational power. The timeline of modern generative AI can be traced back to 2017, with the publication of the seminal research paper "Attention Is All You Need" by Google researchers. This paper introduced the Transformer architecture, which allowed models to process data in parallel and understand the context of words in relation to one another far more effectively than previous Recurrent Neural Networks (RNNs).
By 2020, the release of GPT-3 demonstrated that scaling these models with billions of parameters could lead to emergent behaviors, such as the ability to write code or reason through logic puzzles. The public launch of ChatGPT in late 2022 served as the "iPhone moment" for the industry, moving AI from back-end enterprise applications to a direct consumer interface. Today, the focus has shifted from mere text generation to multi-modal capabilities—where AI can see, hear, and act—and the development of "agents" capable of executing multi-step workflows with minimal human intervention.
1. Large Language Models (LLMs): The Engines of Prediction
At the heart of the current AI boom are Large Language Models (LLMs). Despite their seemingly sentient responses, LLMs are fundamentally sophisticated probabilistic engines. These models are trained on massive datasets—petabytes of text including books, scientific journals, and web content—to identify patterns in human language.
The core function of an LLM is "next-token prediction." When a user inputs a query, the model calculates the statistical probability of the next most likely word (or part of a word) based on the preceding context. By repeating this process thousands of times per second, the model constructs coherent, human-like sentences. Industry leaders like NVIDIA and OpenAI have noted that the "intelligence" perceived by users is actually an emergent property of massive scale; when a model has trillions of parameters, its ability to map the relationships between concepts becomes indistinguishable from reasoning to the average observer.

2. Hallucinations: The Challenge of Probabilistic Error
One of the most significant hurdles in AI adoption is the phenomenon known as "hallucination." Because LLMs are designed to generate text that is statistically plausible rather than factually verified, they can produce statements that are grammatically perfect but entirely false. A model might invent a legal precedent, cite a non-existent medical study, or provide a functional but fake URL.
Data from Vectara’s Hallucination Leaderboard suggests that even the most advanced models have a hallucination rate ranging from 1.5% to 5%, depending on the complexity of the task. This occurs because the model prioritizes the "flow" of language over a database-style lookup. As AI integrates further into critical sectors like healthcare and law, mitigating these errors through rigorous testing and human-in-the-loop oversight remains a primary focus for developers.
3. Retrieval-Augmented Generation (RAG): Grounding AI in Reality
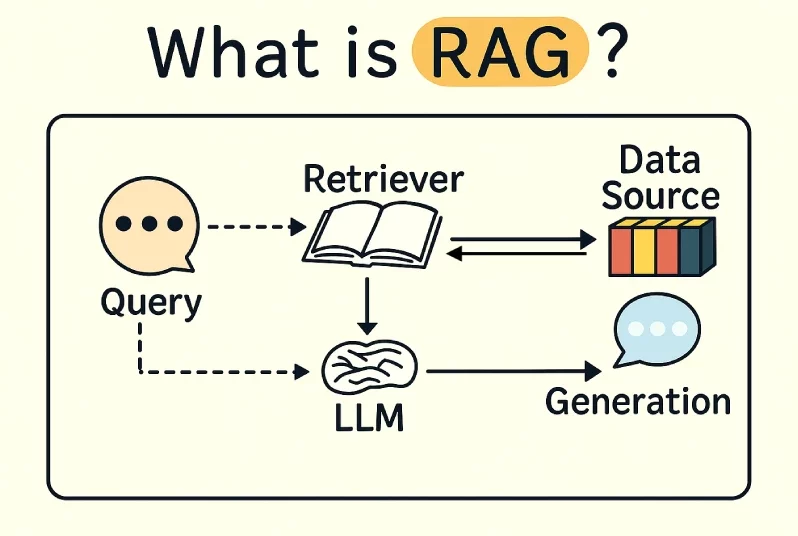
To combat hallucinations and the limitations of "static" knowledge, the industry has turned to Retrieval-Augmented Generation (RAG). Most LLMs have a "knowledge cutoff," meaning they are unaware of events that occurred after their training data was finalized. RAG solves this by connecting the AI to an external, live data source—such as a company’s private cloud, a news feed, or a specific database.
When a query is made in a RAG-enabled system, the AI first "retrieves" relevant documents from the trusted source and then "generates" an answer based solely on that information. This process ensures that the AI provides citations and remains grounded in verifiable facts. According to McKinsey, RAG is currently the preferred architecture for enterprise AI because it allows businesses to use general-purpose models with their proprietary, up-to-date data without the need for expensive retraining.
4. Prompt Engineering: The Art of Structured Instruction
As AI tools become more common, "Prompt Engineering" has emerged as a critical skill set. A prompt is the specific set of instructions provided to the AI. Because LLMs are sensitive to context, the phrasing of a request can drastically alter the quality of the output.
Effective prompting often involves "Few-Shot Prompting" (providing examples) or "Chain-of-Thought" prompting (asking the AI to explain its reasoning step-by-step). Professional journalistic standards for AI interaction suggest that clarity, role-assignment (e.g., "Act as a senior editor"), and constraint-setting are the most effective ways to reduce generic outputs and improve utility.
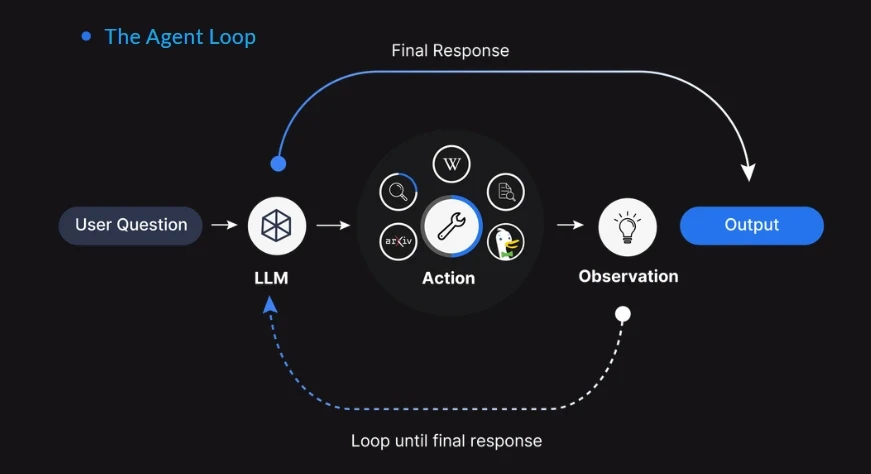
5. AI Agents: From Conversation to Action
The transition from "Chatbots" to "AI Agents" represents the next frontier of the technology. While a standard chatbot responds to a prompt with text, an AI agent is designed to achieve a goal by executing actions across different software environments. An agent might be tasked with "planning a business trip," which would require it to search for flights, check a calendar, compare hotel prices, and send a summary to a manager.
Companies like Microsoft and Salesforce are heavily investing in agentic workflows. These systems use the LLM as a "reasoning engine" to decide which tools to use and when. The implications for productivity are profound, as agents can theoretically handle the "drudge work" of administrative tasks, allowing human workers to focus on high-level strategy.
6. Generative AI: The Creative Shift
Generative AI is a subset of artificial intelligence that focuses on creating new content, rather than just analyzing existing data. Traditional AI was largely "discriminative"—used to classify data (e.g., "Is this image a cat?"). Generative AI, however, creates brand-new data (e.g., "Generate an image of a cat in the style of Van Gogh").
This technology extends beyond text to include images (Stable Diffusion, Midjourney), video (Sora), and audio. The creative industry has reacted with a mix of optimism and concern, leading to ongoing debates regarding copyright and the "fair use" of training data. Legal experts suggest that the coming years will see landmark court cases that define the boundaries of how generative models can utilize human-created intellectual property.
7. Tokens and Context Windows: The Economics of AI Memory
Technically, AI models do not process words; they process "tokens." A token is a numerical representation of a chunk of text. In English, 1,000 tokens typically equate to about 750 words. This is the unit of measurement for both the cost of using AI and the "Context Window."
The Context Window is the model’s short-term memory—the total amount of information it can "keep in mind" during a single session. If a conversation exceeds the context window, the model will begin to "forget" earlier parts of the interaction. Modern models have seen a massive expansion in this area; for instance, Google’s Gemini 1.5 Pro can process up to 2 million tokens, roughly equivalent to several hours of video or thousands of pages of text, in a single prompt.

8. Fine-Tuning: Specializing General Intelligence
While base models are generalists, "Fine-Tuning" is the process of specializing them for specific tasks. This involves taking a pre-trained model and performing additional training on a smaller, targeted dataset. For example, a general model might be fine-tuned on legal briefs to become an expert in contract law. This is more cost-effective than building a model from scratch and allows organizations to customize AI behavior to match their specific tone, style, or technical requirements.
9. Embeddings: The Mathematical Map of Meaning
To understand relationships between concepts, AI uses "Embeddings." This involves converting words or images into long strings of numbers (vectors) and placing them in a multi-dimensional mathematical space. In this "vector space," words with similar meanings—like "doctor" and "physician"—are placed close together, even if they share no letters. This allows the AI to understand synonyms, nuances, and cultural context, forming the backbone of how AI searches for and retrieves information.
10. Broader Impact and Ethical Implications
The rapid deployment of these ten technologies has sparked a global conversation on safety and ethics. Industry leaders, including Sam Altman of OpenAI and Demis Hassabis of Google DeepMind, have called for a balanced approach to regulation that encourages innovation while mitigating risks like deepfakes, algorithmic bias, and job displacement.
Supporting data from the World Economic Forum suggests that while AI may displace 85 million jobs by 2025, it is also expected to create 97 million new roles. The broader implication is a shift in the human labor market toward "AI fluency"—the ability to work alongside these systems effectively. As the technology moves from novelty to utility, the focus is shifting from what AI can do to how it should be integrated into the fabric of society.
In conclusion, the "maze" of artificial intelligence becomes significantly more navigable when these core concepts are understood not as magic, but as advanced mathematics and engineering. As the technology continues to evolve, the ability to distinguish between an LLM’s prediction and an agent’s action will be a defining characteristic of the modern digital citizen.