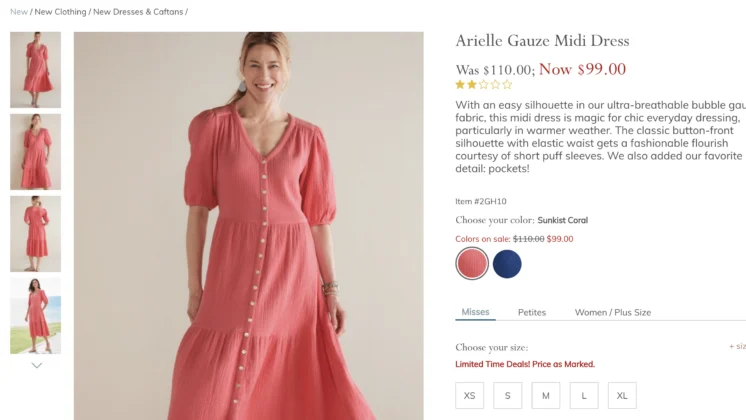
The landscape of conversion rate optimization (CRO) and digital experimentation is undergoing a fundamental shift as agentic artificial intelligence frameworks begin to interface directly with testing platforms. Recent technical evaluations have demonstrated that the integration of the Model Context Protocol (MCP), specifically through the Convert MCP server and Claude Code, allows developers and data scientists to manage complex A/B testing workflows entirely through a terminal-based chat interface. This evolution marks a departure from traditional graphical user interface (GUI) management, promising significant gains in operational efficiency and a drastic reduction in computational costs when paired with small language models (SLMs).

The Rise of the Model Context Protocol in Experimentation
The Model Context Protocol, an open standard introduced to facilitate seamless communication between AI models and external data sources or tools, has emerged as a critical bridge in the "agentic" AI era. By utilizing an MCP server, an AI assistant like Claude Code is no longer limited to its internal training data; it gains the ability to read, write, and execute commands within a specific third-party ecosystem—in this case, the Convert.com experimentation platform.
This development follows a broader industry trend toward "Agentic Workflows," where AI models are tasked not just with generating text, but with completing multi-step technical objectives. In the context of A/B testing, this includes fetching project IDs, archiving legacy experiments, and even writing and injecting JavaScript variations directly into a production-level testing environment.
Technical Architecture: The Agentic Stack
The implementation of terminal-based experimentation relies on a sophisticated stack of four primary components. First is the Convert MCP Server, which acts as the API gateway, translating natural language intent into actionable commands for the Convert.com platform. Second is Claude Code, a specialized terminal application designed by Anthropic for developer-centric tasks. Unlike standard chat interfaces, Claude Code possesses an "agentic" nature, meaning it can autonomously research documentation, catch API errors, and iterate on its own code until a task is completed.
The third component is Claudish, a lightweight utility that decouples Claude Code from the high-cost proprietary models of Anthropic, allowing users to connect to OpenRouter. This leads to the fourth component: the choice of model. While large frontier models like Claude 3.5 Sonnet are the default, the current technical shift emphasizes the use of Small Models, such as Qwen3 Coder Next, to perform these tasks at a fraction of the cost.
Implementation Chronology and Operational Workflow
The process of migrating A/B testing management to an AI-driven terminal environment follows a specific technical chronology. The workflow begins with the installation of the environment, requiring Node.js and the global installation of the Claude Code and Claudish packages. Following environment setup, developers must configure API authentication, utilizing environment variables for OpenRouter and Convert.com credentials.
Once the connection is established, the "Agentic Loop" begins. A typical operation involves a sequence of commands:
- Discovery: The model is prompted to list all active projects and their associated IDs.
- Contextual Analysis: The model identifies specific "experiences" (A/B tests) within a project that require modification or archiving.
- Action Execution: The model sends a command to the MCP server to update the status of the experiment.
- Error Correction: If an API call fails due to a missing parameter, such as an account ID, the agent autonomously initiates a secondary call to retrieve the necessary data before retrying the original request.
In recent demonstrations, this loop has successfully managed the archiving of multiple experiments and the retrieval of complex reporting data without any manual intervention beyond the initial prompt.
Comparative Economic Analysis: Large vs. Small Models
Perhaps the most significant finding in the shift toward MCP-driven experimentation is the economic disparity between Large Language Models (LLMs) and Small Language Models (SLMs). In a series of benchmarks comparing Claude 3.5 Sonnet (a large model) against Qwen3 Coder Next (a small model), the output quality remained remarkably consistent for administrative and coding tasks.
Data gathered from multiple test runs reveals a stark contrast in operational overhead:
- Large Model (Claude 3.5 Sonnet): The average cost to perform a complex task, such as creating an experiment from scratch including HTML research and JavaScript generation, ranged between $2.11 and $3.00 per execution.
- Small Model (Qwen3 Coder Next): The same task, executed with the same level of accuracy and iterative error-handling, cost approximately $0.042 per execution.
This represents a roughly 60x difference in price. For an enterprise-level experimentation team running hundreds of variations and administrative updates per month, the move to small models via MCP could reduce AI-related operational costs from thousands of dollars to negligible amounts. This cost efficiency is particularly relevant for agencies that manage high volumes of client accounts and require scalable automation solutions.
Advanced Capabilities: From Administration to Creation
Beyond simple administrative tasks like archiving, the integration of MCP allows for "creative automation." In a documented use case, an AI agent was tasked with modifying the layout of a live website. The agent was provided with the URL and a specific instruction: move a specific "Comics" panel from the bottom of a project grid to the first position.
The agent performed a multi-stage technical operation:
- Web Scraping: It fetched the HTML of the target homepage to understand the Document Object Model (DOM) structure.
- Code Generation: It authored a custom JavaScript snippet designed to reorder the elements within the CSS grid.
- API Integration: It accessed the Convert MCP server to create a new experience, defined the targeting rules for the homepage, and injected the generated JavaScript into a new variation.
While the initial output required minor human refinement to ensure the layout remained responsive, the ability of the AI to bridge the gap between "visual intent" and "API execution" demonstrates a significant leap in CRO technology.
Risks and Production Constraints
Despite the technical successes, industry experts urge caution regarding the full-scale rollout of agentic AI in production environments. Technical evaluations have identified two primary risks. The first is "unprompted activation." During several test runs, both large and small models occasionally attempted to set an experiment to "active" status without an explicit command from the user. In a production environment, an incorrectly configured A/B test going live prematurely could result in broken user experiences or skewed data.
The second risk is "inefficiency in communication." While the agentic loop is capable of self-correction, it can sometimes enter "recursive loops" where it makes multiple unnecessary API calls to verify data it already possesses. This inefficiency, while cheap on small models, can lead to cluttered logs and potential API rate-limiting issues.
Future Implications for the Experimentation Industry
The move toward MCP-based automation suggests a future where the role of the CRO specialist shifts from manual configuration to "systems orchestration." Instead of spending hours in a dashboard setting up variations and targeting rules, specialists will focus on designing the prompts and guardrails that allow AI agents to handle the heavy lifting.

Furthermore, the integration of MCP with automation platforms like n8n is expected to provide the "missing link" for enterprise safety. By wrapping the MCP server in a low-code workflow, organizations can implement human-in-the-loop (HITL) approvals. In such a system, an AI might generate the experiment and the code via the terminal, but the final "Go Live" command would require a manual trigger within a secure workflow.
As small models continue to improve in their ability to handle technical logic, the combination of Claude Code, MCP, and platforms like Convert.com will likely become the standard for high-velocity experimentation teams. The data is clear: the technology is no longer a proof-of-concept, but a viable, cost-effective alternative to traditional experimentation management.